|
5. 語音識別前言上一篇我們舉了一個很簡單的範例,判斷聲音是bed、cat 或是 happy,實務上它可以應用在一些場域,例如,PowerPoint簡報時,我們可以用聲音下指令,例如『上、下、Play、Stop』代表『上一頁、下一頁、撥放影片、停止播放』,又譬如操作機器人,也可以用聲音使它前後左右移動,這種指令式的應用是否需要以 Neural Network 技術實踐,是否殺雞用牛刀,就見仁見智了。 LSTM範例擴展上一篇我們使用 CNN 演算法作語音辨識,其實,也可以用RNN(LSTM)作辨識,因為 LSTM 會考慮前面的訊號,程式節錄如下: from __future__ import division, print_function, absolute_import import tflearn import speech_data learning_rate = 0.0001 training_iters = 300000 batch_size = 64 width = 20 height = 80 classes = 10 batch = word_batch = speech_data.mfcc_batch_generator(batch_size) X, Y = next(batch) trainX, trainY = X, Y testX, testY = X, Y net = tflearn.input_data([None, width, height]) net = tflearn.lstm(net, 128, dropout=0.8) net = tflearn.fully_connected(net, classes, activation='softmax') net = tflearn.regression(net, optimizer='adam', learning_rate=learning_rate, loss='categorical_crossentropy') model = tflearn.DNN(net, tensorboard_verbose=0) while 1: model.fit(trainX, trainY, n_epoch=100, validation_set=(testX, testY), show_metric=True, batch_size=batch_size) _y=model.predict(X) print (_y) print (y)
程式說明- 這個程式 speech2text-tflearn.py 可從這裡下載,訓練資料會用到 curl、untar 等Linux指令,適合在Linux 環境下執行。
- 程式邏輯與上一篇幾乎相同,只是把 CNN(Conv2D/MaxPooling2D) 換成 LSTM 層而已。
- 同一目錄下的 speech_data.py 為公用函數庫,會被主程式 speech2text-tflearn.py 呼叫。
- 本程式使用 TFLearn ,與 Keras 同為 metat framework,讀者其實可以把上述程式改為 Keras based,應該也不難。
擴展從這個簡單的範例出發,大家應該都會想到一些應用擴展上的問題: - 範例只辨識單字,如果要辨識整句呢?
- 如果要辨識整段演講呢?
短句辨識一個簡單的作法就是請講者說話速度慢一點,中間自然會產生靜音,我們就可以將 input 切成數段,之後辨識每一段為哪一個單字,組合起來即為整句內容,這種作法中文會比外語容易,因為中文都是單音節,要切割比較簡單。另外,為了提高準確,可以有兩種作法: - CNN + LSTM:利用 CNN 萃取特徵,辨識單字,再利用『自然語言處理』提到的 LSTM 模型,它會考慮上下文,就可以較準確的辨識出整句內容了,可參考『CNN Long Short-Term Memory Networks』。
- 利用『自然語言處理』的前置處理及語意分析,判斷可能性較大的內容。例如,使用 spaCy 套件,簡單範例如下:
import spacy from spacy import displacy nlp = spacy.load('en') doc = nlp(u'I like the movie very much.') displacy.serve(doc, style='dep')
執行以上程式後,在瀏覽器輸入下列網址,結果如下圖,它可以利用詞向量及語料庫分析,我們可以進一步根據語意分析判斷,那些候選句是較合理的。
http://localhost:5000/
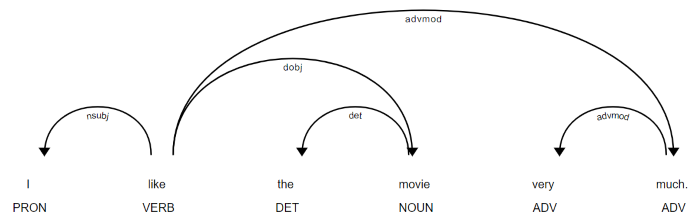
圖. spaCy Visualizer 以上方法在短句辨識上,實踐上應該很容易,但是,較長的字句就會力有未逮了。 自動語音識別(Automatic Speech Recognition)架構如果針對整段演講進行辨識,勢必要有一個較完整的架構,除了靠『語音信號處理』外,尚須借重『自然語音處理』去矯正辨識出來的結果,才能畢其功於一役,以下就是一個較完整的架構。
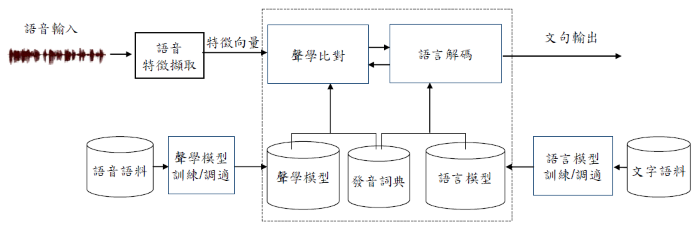
圖. 自動語音識別(Automatic Speech Recognition)架構,圖片來源:現階段大詞彙連續語音辨識研究之簡介 從另一個角度,以各模組功能來看:
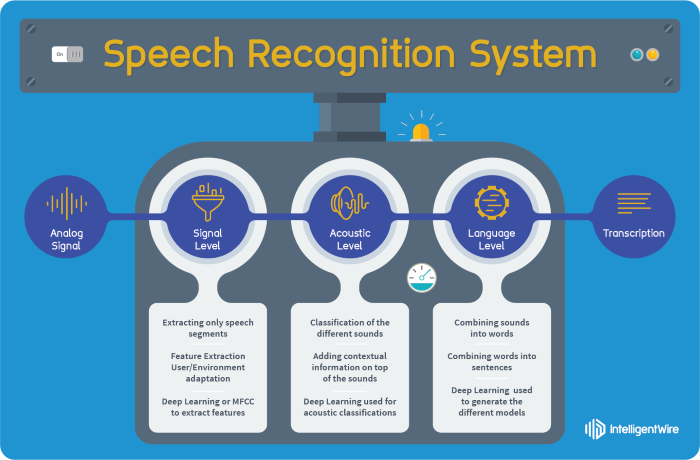
圖. 分三個層次,信號處理(Signal)、聲學處理(Acoustic)、語言處理(Language),圖片來源:Kaldi now offers TensorFlow integration 『現階段大詞彙連續語音辨識研究之簡介』一文有相當詳盡的說明,筆者還是秉持初衷,用圖說故事,整理如下: 語音特徵擷取(Feature Extraction) - 以示波器測得的『時域』(Time Domain)信號
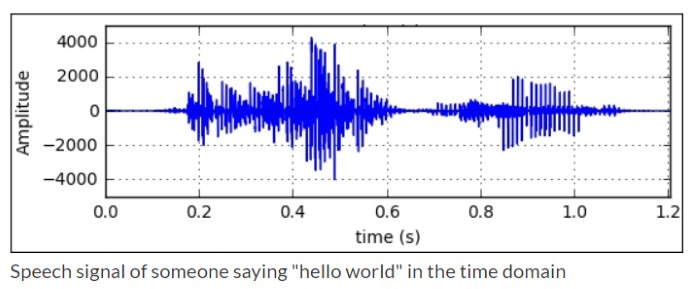 - 利用『快速傅立葉轉換』(Fast Fourier Transform,FFT)轉為『頻域』(Frequency Domain)信號
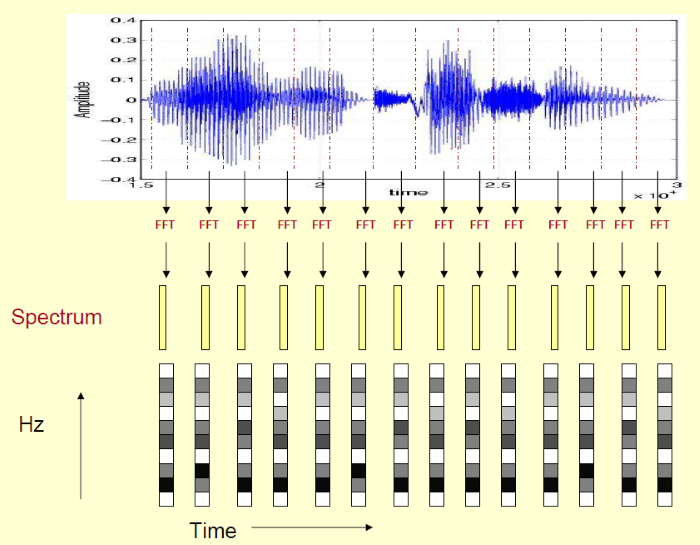 - 再抽樣,轉為 MFCC 特徵向量
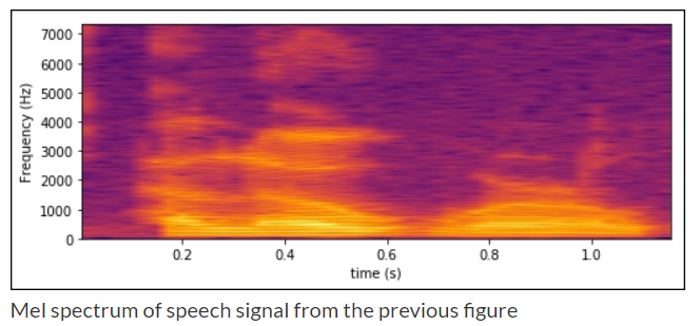
聲學比對 -- 聲學模型(Acoustic model):傳統上使用『隱藏馬可夫模型』(Hidden Markov Model,HMM) 技術,依照音素(Phoneme)、音節的特徵向量比對,找出機率最大(最有可能)的單字,後來,又結合『高斯混合模型』(Gaussian mixture model,GMM),成為經典的 GMM-HMM 模型。最近 Neural Network 崛起,各種演算法及模型紛紛出籠,例如 RNN-HMM、Connectionist Temporal Classification (CTC)、Attention-based models 等。 語言解碼(Decode) -- 語言模型(Language model):經過聲學分析出來的字句,可能會有多種候選字句,例如下圖,再透過語料庫比對及語言模型,進行解碼找出機率最大(最有可能)的文句。
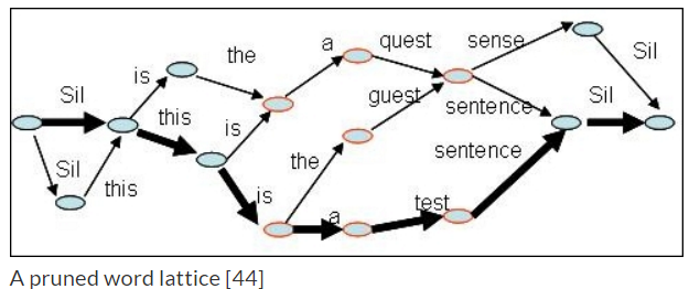
以上圖形來自 - Speech Processing
- Python Deep Learning
結語自動語音識別(Automatic Speech Recognition)與自然語言處理的關係是密不可分的,辨識出來的結果還是要依據語意、文法及大量標註的語料庫,才能正確的辨識,進而了解其意,最後才能有人機對話的可能,讀到這裡,範圍有點大,已經有點痛苦,下次再加油吧。
|
