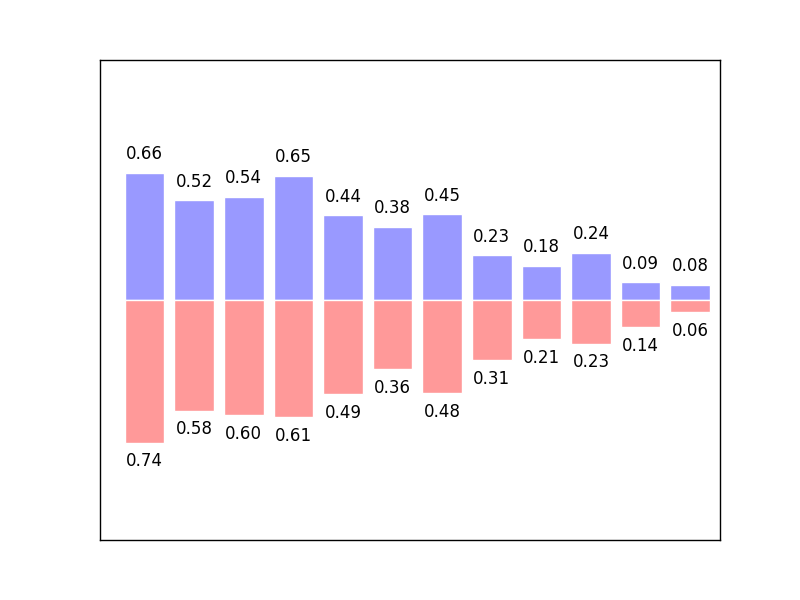
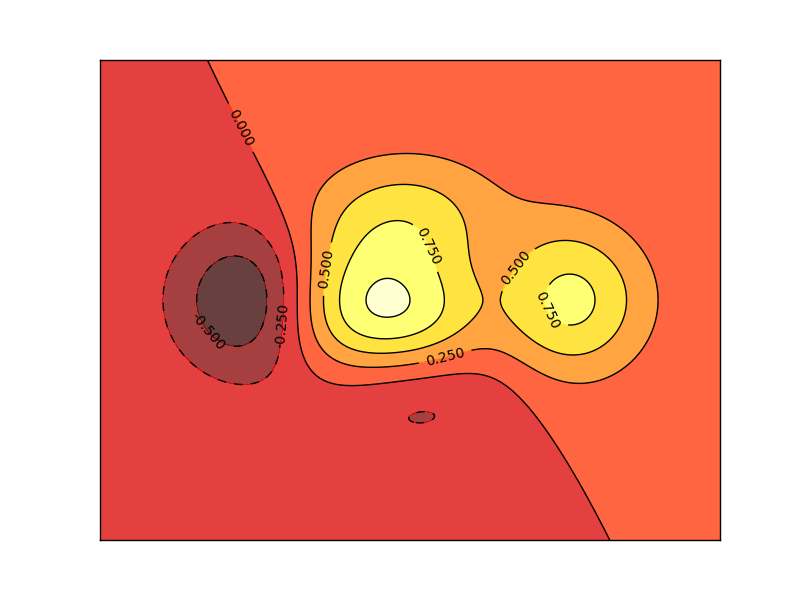
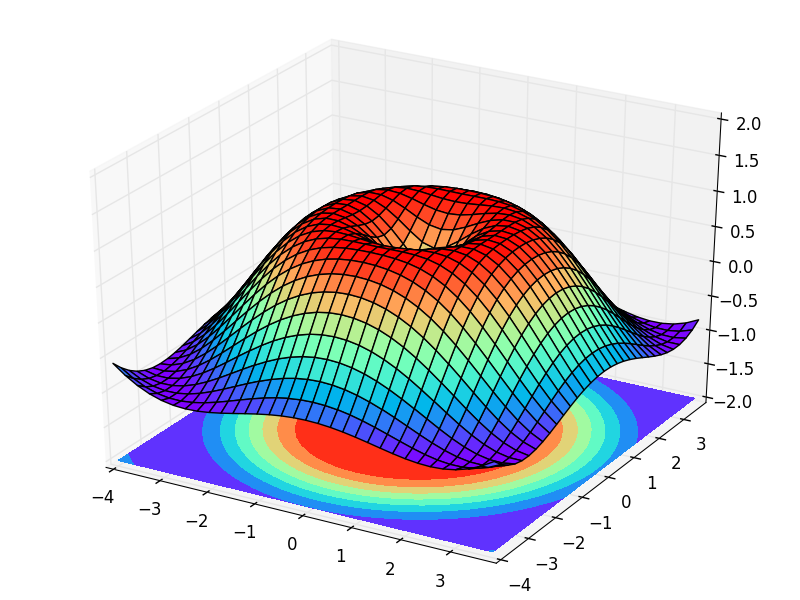
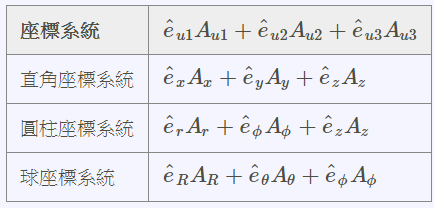
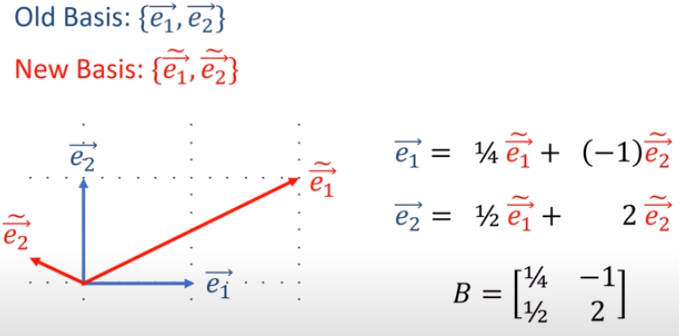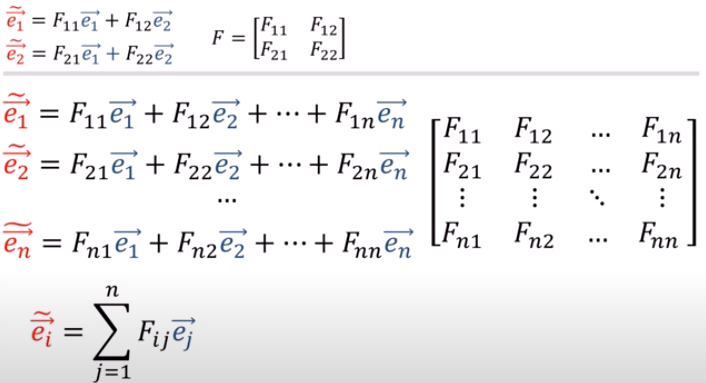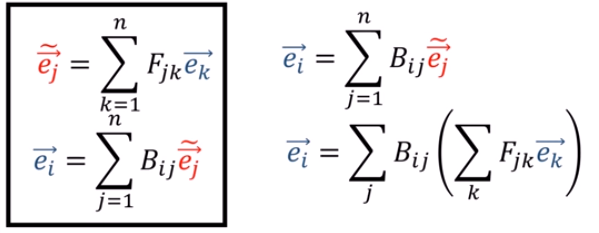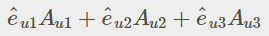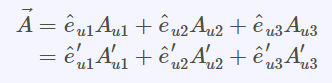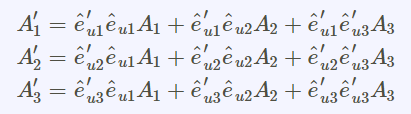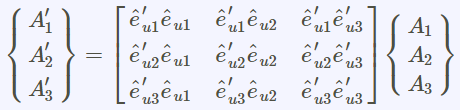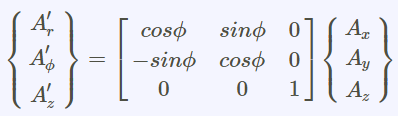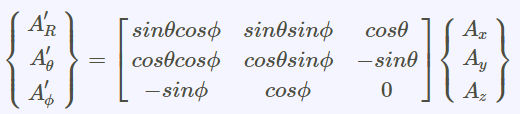課程概論 的需求量大,容易結合至 數據 處理工具; Python 可以支援的程式庫有Theano和Tensorflow, 数据分析 的NumPy和Pandas。 https://zh-tw.facebook.com/groups/yenlung.live/
https:/join.butter.us/yenlung/2022-fg-ai
1 【深度學習實作重點和原理】介紹神經網路的基本概念
2
【用Colab打造第一個神經網路】介紹 Colab 環境的使用, 建立一個自己的神經網路, 並用 Gradio 瞬間打造一個 web app!
3
【CNN 的原理和遷移式學習】CNN 和遷移式學習的概念
4
【打造自己的圖形辨識神經網路】怎樣用遷移式學習, 打造自己的圖形辨識 AI!
5
【AI 可以生成文章、還可以寫歌!】電腦怎麼處理人類的文字語言呢? 電腦可以幫我們寫文章、創作歌曲嗎?
6
【打造人臉辨識系統】介紹用神經網路做人臉辨識的原理, 並且用一個叫 DeepFace 的套件快速實作!
https://nbviewer.org/github/yenlung/
選擇 Python-AI-Book
參考資料來源 2:
陳擎文教學網:python大數據分析與資料爬取 https://acupun.site/lecture/python_data/index.htm
PART A:
Ex3-0 & 中文顯示 [
download ]
chp1.前言,執行python三種方法,安裝anaconda
chp2.數據資料視覺化1(Matplotlib模組)
chp3.數據資料視覺化2(Pandas模組)
chp4.數據資料視覺化3(plotly模組)
chp5.矩陣運算數學函數庫(Numpy)
PART B:
chp7.資料儲存與讀取2(SQLite、MySQL)
chp8.資料儲存與讀取3(存取xml,json)
PART C:
chp10.網絡大數據爬取與分析2(網路爬蟲:BeautifulSoup)
chp11.網絡大數據爬取與分析3(Pandas數據分析與資料存取)
chp12.網絡大數據爬取與分析4(用正規式搜尋網頁的email,jpg訊息)
chp13.網絡大數據爬取與分析5(Selenium自動化網頁操作)
chp14.python視窗(GUI Tkinter)
chp16.台灣股票市場個股分析統計圖
chp17.用LINE傳送即時股價
chp18.使用pandas模組實作PM2.5即時監測
chp19.米其林餐廳指南下載
chp20.API建立於鄉鎮市區天氣預報
教學網站
chp1.前言,安裝anaconda 1.使用python的三種方法 2.Anaconda下載點 3.安裝anaconda 4.Anaconda cmd指令 5.建立Anaconda虛擬環境 6.使用Spyter編譯器 7.網頁版python編輯器jupyter notebook 8.其它線上雲端可編譯的python平台 1.前言
Python堪稱是大數據與AI時代的最重要程式語言,在資料處理上有著非常重要的地位。而隨著AI的興起,讓傳統的零售業、金融業、製造業、旅遊業,以及政府都爭相投入,無不希望能運用數據分析與預測來協助決策方向,也讓新興的數據分析師、資料分析師成為熱門職業,因此本課程將講解如何使用網絡爬蟲技術以掌握資料爬取分析、視覺化呈現,以及儲存交換應用的關鍵技術。 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
2.執行python的三種方法
1.要編寫python有三種的方法:python官網下載 到Anacond官網下載安裝 使用python官網線上shell 使用repl線上python 3.Anaconda下載點
Anacond官網
3.安裝anaconda 3.安裝anacondahttps://www.anaconda.com/ https://www.anaconda.com/products/individual 4.Anaconda prompt:cmd指令 4.使用anaconda prompt:直接下cmd指令 5.用Anaconda prompt來建立虛擬環境
5.使用Anaconda prompt來建立虛擬環境 6.使用Spyter編譯器
6.使用Spyter:編譯器 7.jupyter notebook網頁版的python編輯器
7.jupyter notebook 8.其它線上雲端可編譯的python平台
8.其它線上雲端可編譯的python平台
chp2.數據資料視覺化1(Matplotlib模組) 目錄 1.Matplotli介紹 Matplotlib常用繪圖的基本語法 範例2-1:畫出(y)串列數據scatter散佈圖 範例2-2:繪圖(x,y)串列數據 範例2-3:繪出紅色色虛線(x,y)圖 6.plt.plot參數 >範例2-4:繪圖兩條線 範例2-5:繪柱狀圖:兩條線 範例2-6:圓餅圖(plt.pie) 範例2-7:總共3個圖,上面一個,下面兩個分割圖 <範例2-8:結合numpy與matplotlib的繪圖,畫出三條線 範例2-9:結合pandas 與 matplotlib畫圖股票線圖 1.Matplotli介紹
1.Matplotli介紹: matplotlib常用繪圖的基本語法
常用繪圖的基本語法: 範例2-1:畫出(y)串列數據scatter散佈圖
2.散點圖,scatter散佈圖:plt.plot程式碼內容 ] 範例2-2:繪圖(x,y)串列數據
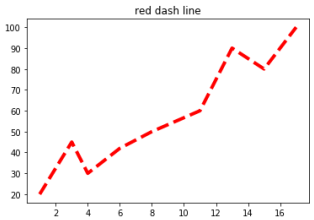
3.範例2-2:繪圖(x,y)串列數據程式碼內容 範例2-3:繪出紅色色虛線(x,y)圖/p>
4.範例2-3:繪出紅色色虛線(x,y)圖程式碼內容 6.plt.plot參數
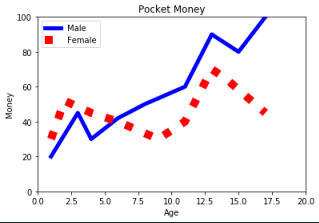
6.plt.plot參數 範例2-4:繪圖兩條線,藍色實線寬5,紅色點線寬10
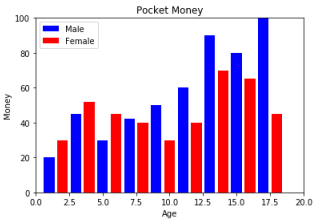
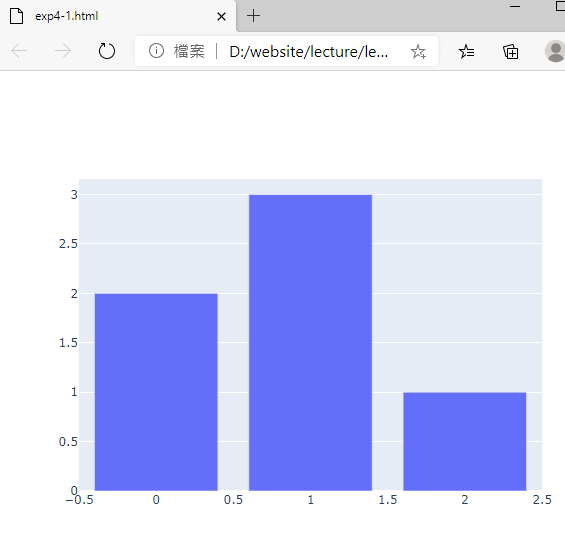
6.範例2-4:繪圖兩條線,藍色實線寬5,紅色點線寬10程式碼內容 範例2-5:繪柱狀圖:兩條線,藍色實線寬5,紅色點線寬10
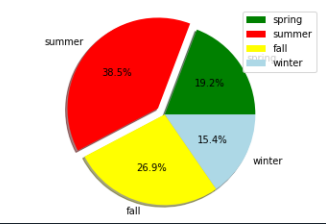
7.柱狀圖(plt.bar)程式碼內容 範例2-6:圓餅圖(plt.pie)顯示春夏秋冬四季的業績%
8.圓餅圖(plt.pie)程式碼內容 範例2-7:總共3個圖,上面一個,下面兩個分割圖
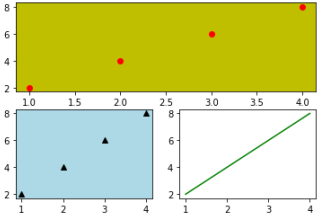
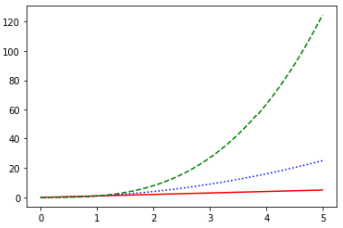
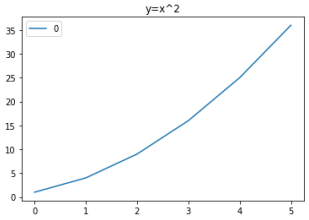
9.切割圖程式碼內容 範例2-8:結合numpy與matplotlib的繪圖,畫出三條線
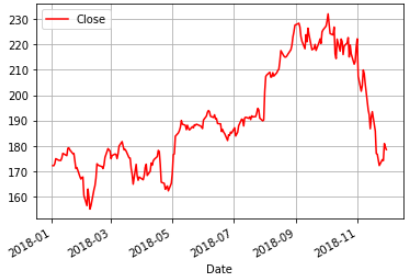
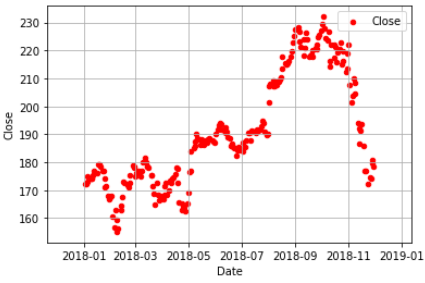
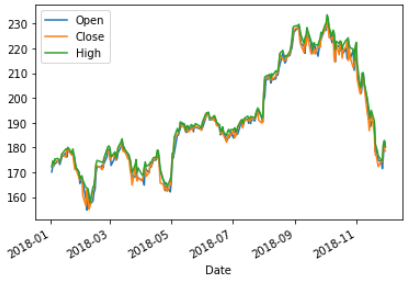
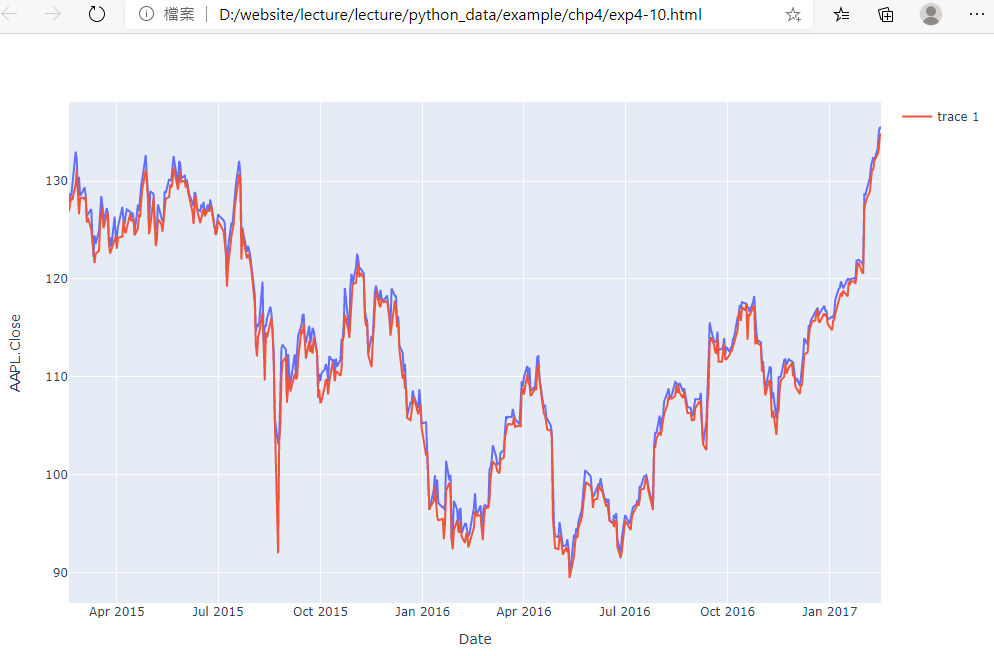
10.結合numpy與matplotlib的繪圖,畫出三條線(y=x,y=x^2, y=x^3)程式碼內容 範例2-9:結合pandas 與 matplotlib畫圖股票線圖(讀取AAPL.xlsx 股票檔案)
13.範例2-9:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
chp3.數據資料視覺化2(Pandas模組) 範例3-1:繪圖(y=x^2)串列數據 範例3-2:繪圖(x,y)串列數據 3.pandas.DataFrame.plot( ) 範例3-3:繪出紅色虛線,線寬4(x,y)圖 範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪圖 範例3-5:如何把兩組線條同時畫在同一張圖上 範例3-6:如何把圖形存檔成p3-6.png 範例3-7:統計同一州的人數柱狀圖顯示 範例3-8:統計同一州人的性別柱狀堆疊圖顯示 範例3-9:印出四位學生的三科成績 範例3-1:繪圖(y=x^2)串列數據
1.範例3-1:繪圖(y=x^2)串列數據程式碼內容 範例3-2:繪圖(x,y)串列數據
2.範例3-2:繪圖(x,y)串列數據程式碼內容 3.pandas.DataFrame.plot( )
3.pandas.DataFrame.plot( ) 範例3-3:繪出紅色虛線,線寬4(x,y)圖
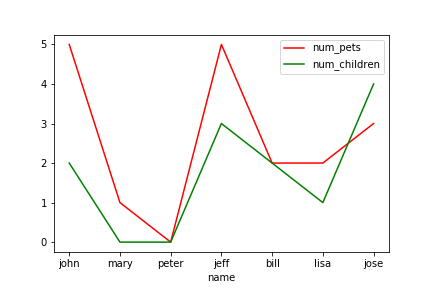
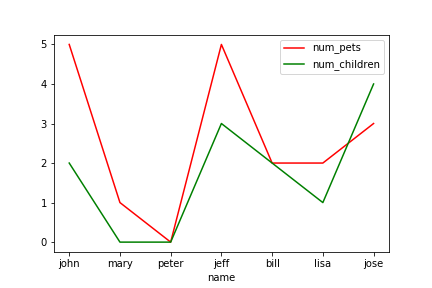
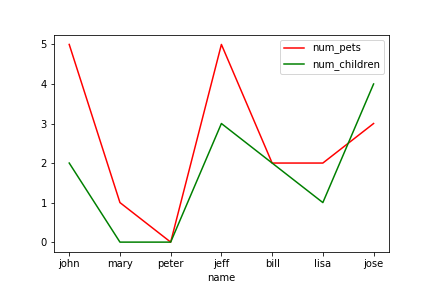
3.範例3-3:繪出紅色虛線,線寬4(x,y)圖程式碼內容 範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪scatter圖,bar圖
4.範例3-4:從DataFrame資料裡面取出num_children vs num_pets來繪scatter圖,bar圖程式碼內容 範例3-5:如何把兩組線條同時畫在同一張圖上
5.範例3-5:如何把兩組線條同時畫在同一張圖上程式碼內容 範例3-6:如何把圖形存檔成p3-6.png
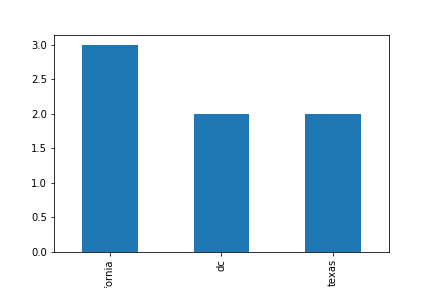
6.範例3-6:如何把圖形存檔成p3-6.png程式碼內容 範例3-7:統計同一州的人數柱狀圖顯示
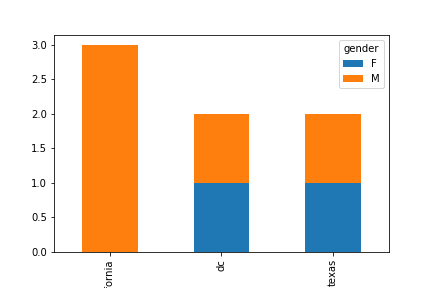
6.範例3-7:統計同一州的人數柱狀圖顯示(state vs name)Bar plot with group by程式碼內容 範例3-8:統計同一州人的性別柱狀堆疊圖顯示
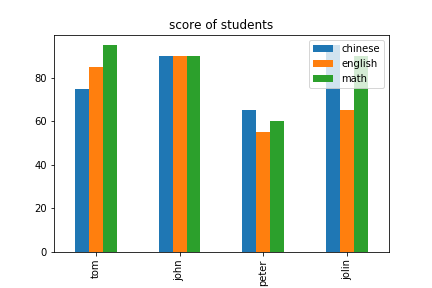
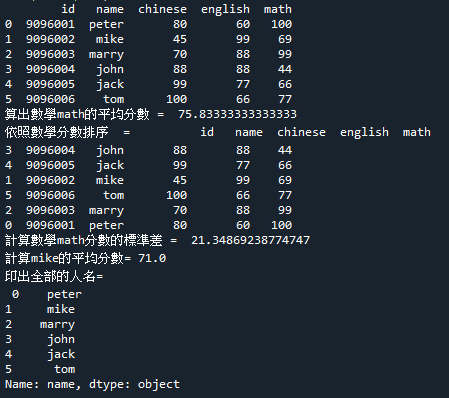
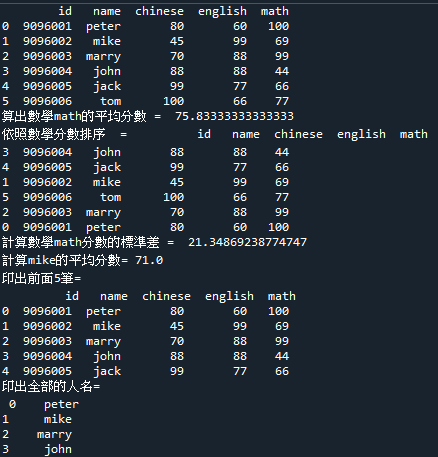
7.範例3-8:統計同一州人的性別柱狀堆疊圖顯示(Stacked堆疊 bar plot with two-level group by)程式碼內容 範例3-9:印出四位學生的三科成績
8.範例3-9:印出四位學生的三科成績程式碼內容
chp4.數據資料視覺化3(plotly,Plotly-Express模組)Containers 1.Plotly,Plotly-Express簡介Containers 2.Plotly,Plotly-Express功能 3.Python-Plotly 安裝 4.顯示結果的方法有兩種 範例4-1:Plotly-Express的結構與指令 範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖 範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖 範例4-4:顯示兩個分割圖形 範例4-5:顯示兩個分割圖形(方法2 範例4-6:在分割圖形新增圖形 範例4-7:express顯示四位學生的總成績 範例4-8:express同時畫出三條圖 範例4-9:安德森鳶尾花卉數據集 例4-10:讀取蘋果股價csv檔為dataFrame 範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績 範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績 範例4-21:3D表面圖:具有輪廓的曲面圖 範例4-22:使用滑動日期欄為Plotly地圖製作動畫 範例4-23:桑基圖 範例4-24:漏斗圖 範例4-25:動畫控制 1.Plotly,Plotly-Express簡介
1.Plotly,Plotly-Express簡介
2.Plotly,Plotly-Express功能:
2.Plotly,Plotly-Express功能:
3.Python-Plotly 安裝
3.Python-Plotly 安裝
4.顯示結果的方法有兩種
4.顯示結果的方法有兩種
範例4-1:Plotly-Express的結構與指令
5.範例4-1:Plotly-Express的結構與指令程式碼內容 程式碼內容
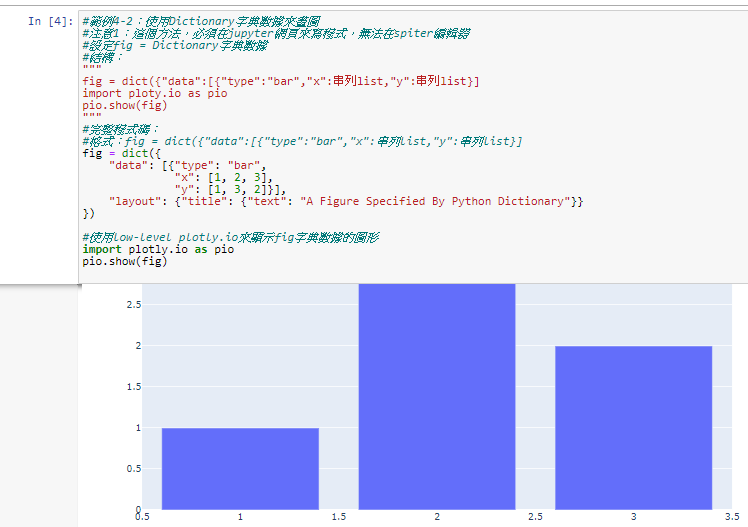
範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖
6.範例4-2:(使用low-level plotly方法)使用Dictionary字典數據來畫圖程式碼內容
範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖
7.範例4-3:(使用top-level plotly方法:plotly.graph_objects)畫出y=[1,3,2]的bar圖程式碼內容
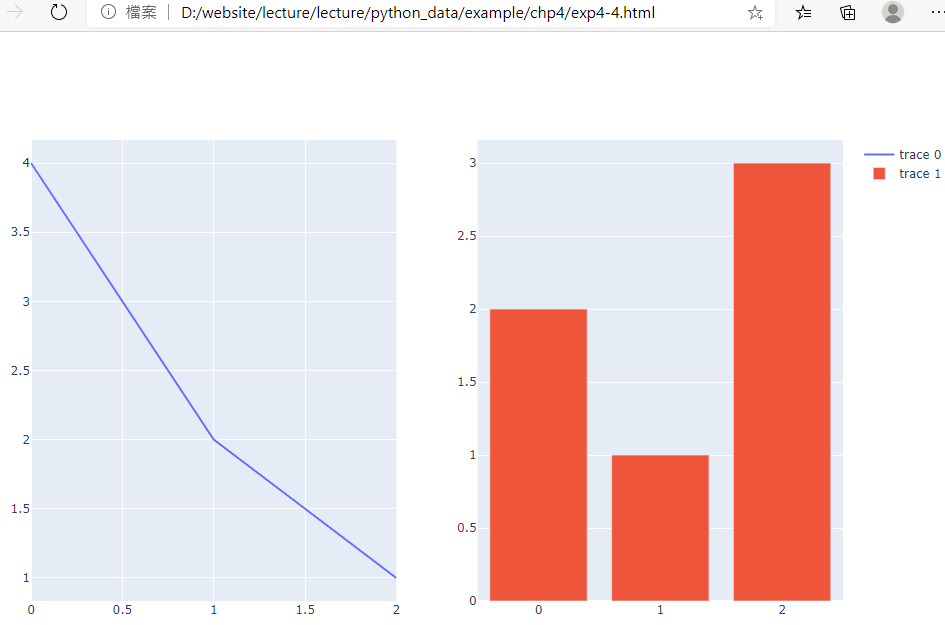
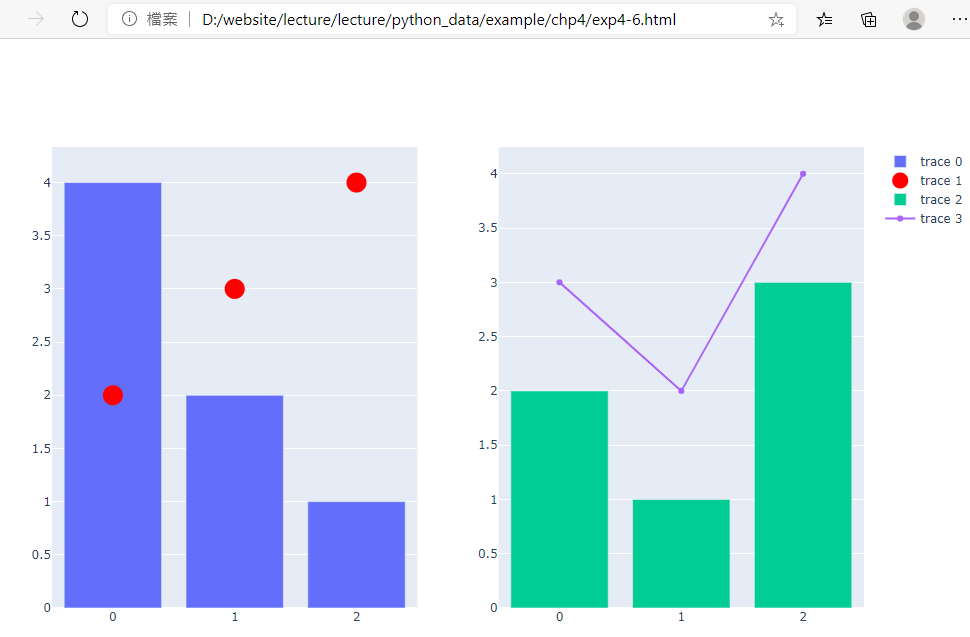
範例4-4:顯示兩個分割圖形
8.範例4-4:顯示兩個分割圖形程式碼內容
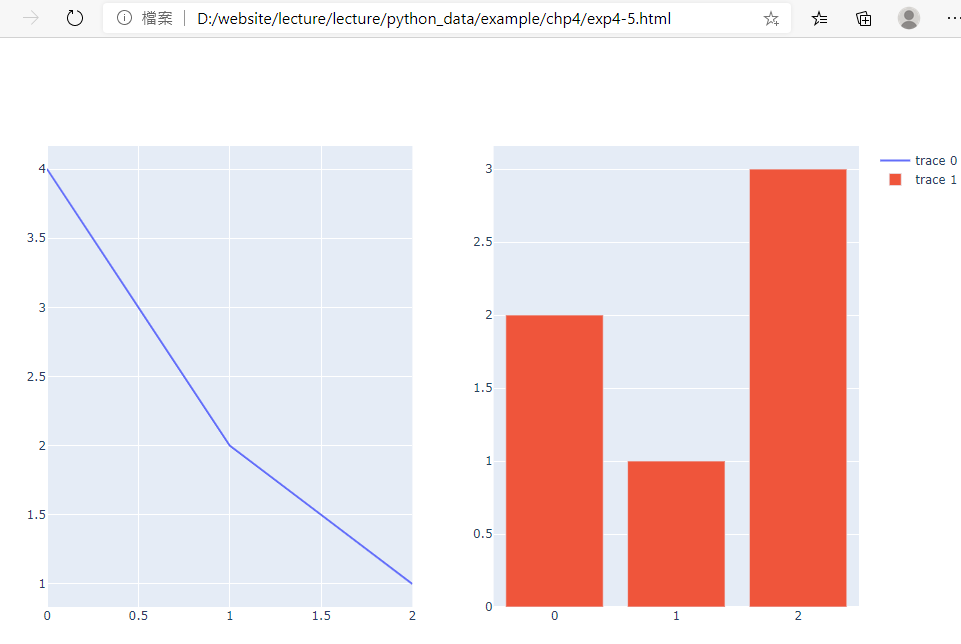
範例4-5:顯示兩個分割圖形(方法2)
9.範例4-5:顯示兩個分割圖形(方法2)程式碼內容
範例4-6:在分割圖形新增圖形(scatte-marker,line)
10.範例4-6:在分割圖形新增圖形(scatte-marker,line)程式碼內容
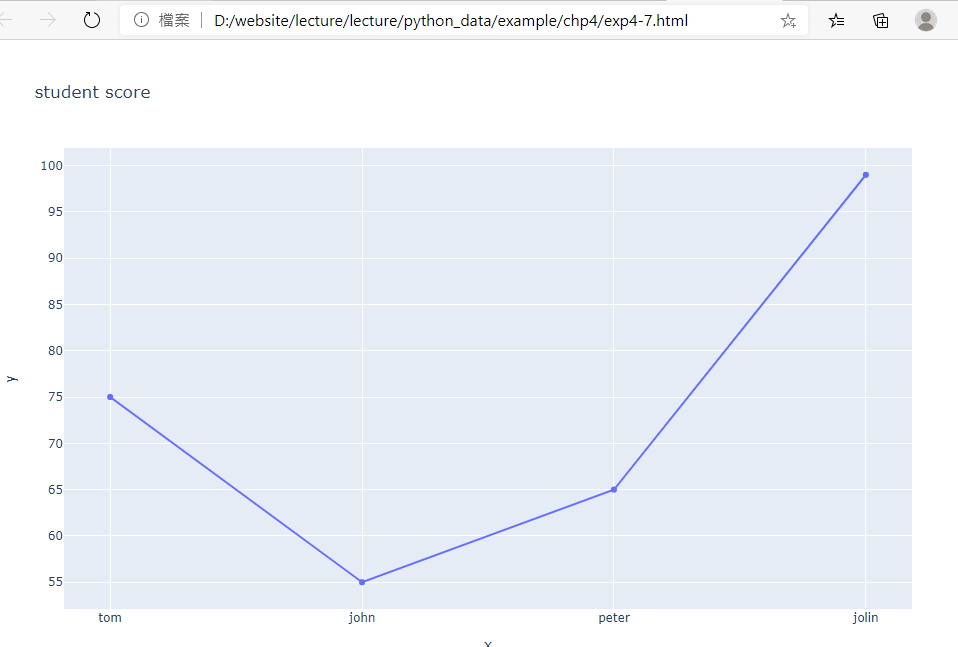
範例4-7:express顯示四位學生的總成績
11.範例4-7:express顯示四位學生的總成績(畫lines+markers)程式碼內容
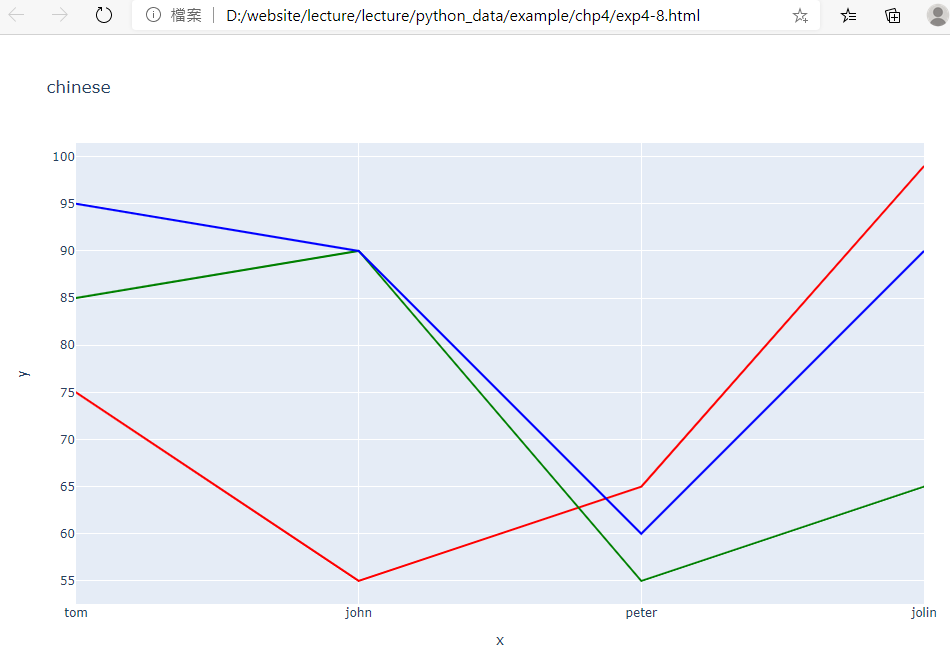
範例4-8:express同時畫出三條圖
12.範例4-8:express同時畫出三條圖(四位學生,三科成績)程式碼內容
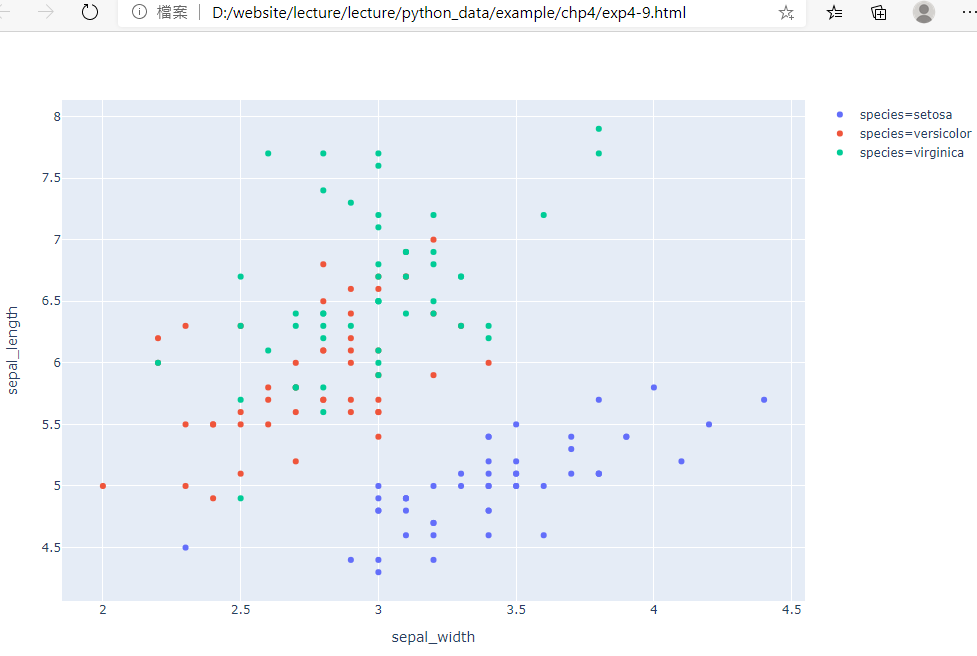
範例4-9:安德森鳶尾花卉數據集
13.範例4-9:安德森鳶尾花卉數據集(Iris flower data set)程式碼內容
例4-10:讀取蘋果股價csv檔為dataFrame,然後用express畫圖
14.例4-10:讀取蘋果股價csv檔為dataFrame,然後用express畫圖程式碼內容
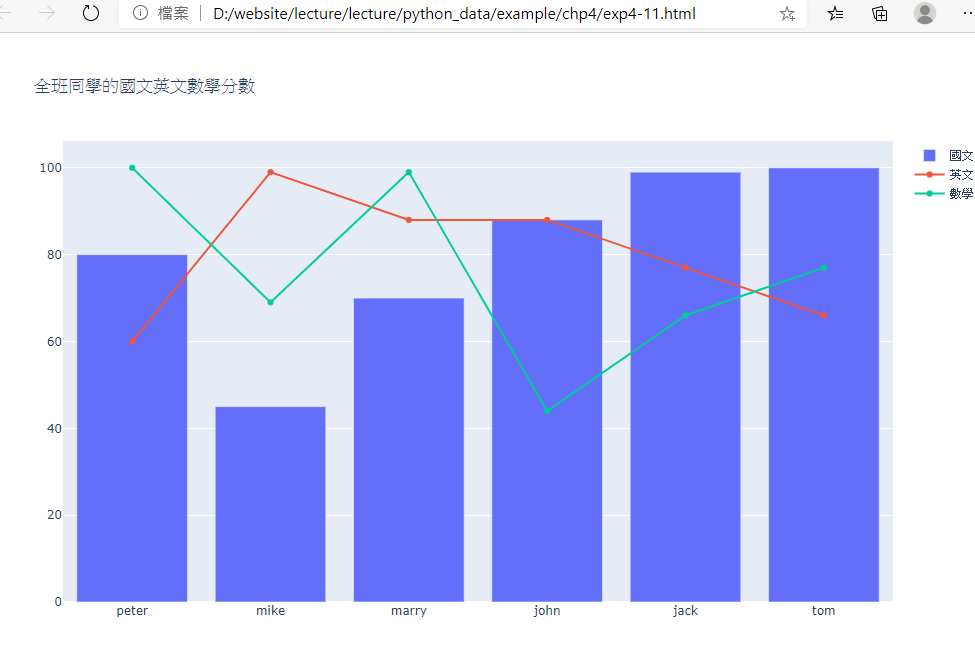
範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績
15-範例4-11:讀取score.csv建立dataFrame,然後用express印出四位學生的三科成績程式碼內容
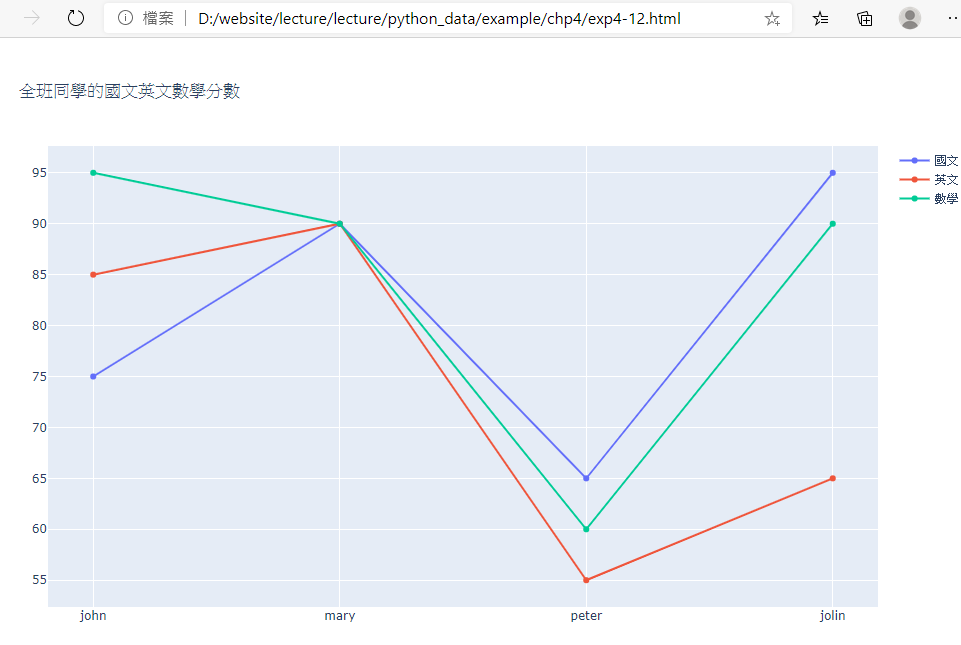
範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績
16.範例4-12:自行建立DataFrame資料集,然後用express印出四位學生的三科成績程式碼內容
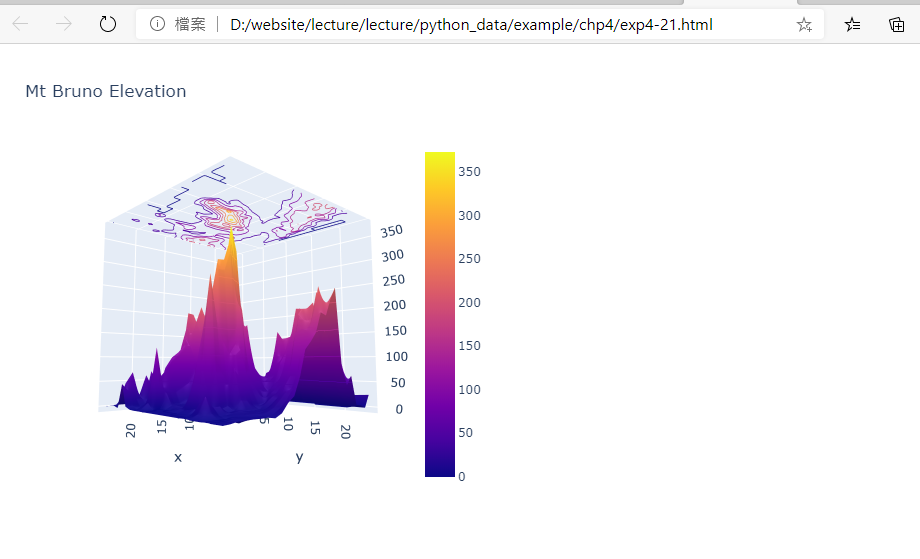
範例4-21:3D表面圖:具有輪廓的曲面圖
21.範例4-21:3D表面圖:具有輪廓的曲面圖程式碼內容
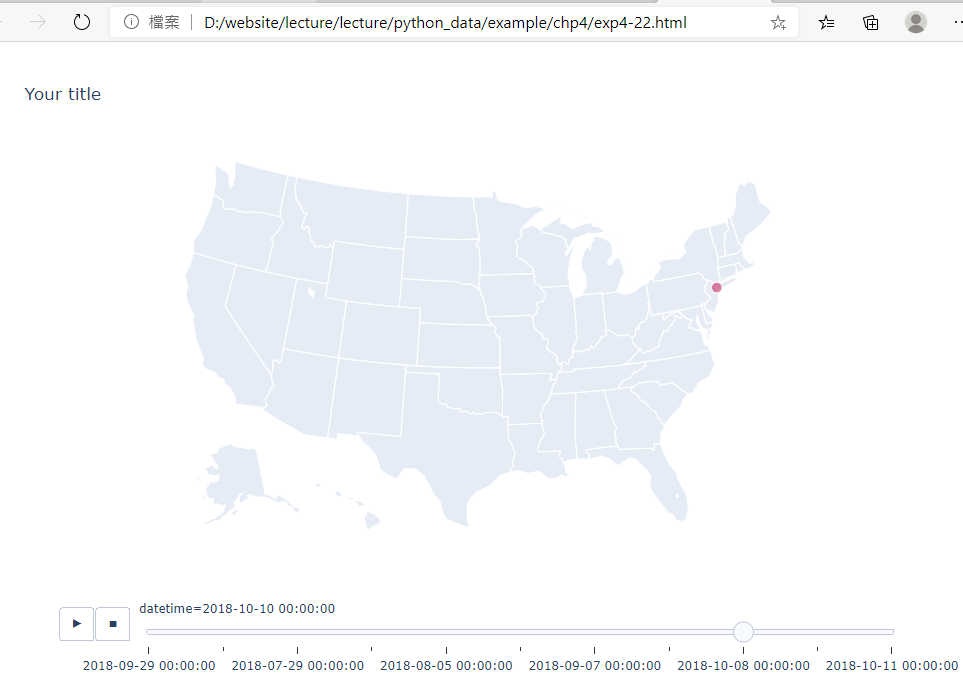
範例4-22:使用滑動日期欄為Plotly地圖製作動畫
22.範例4-22:使用滑動日期欄為Plotly地圖製作動畫程式碼內容
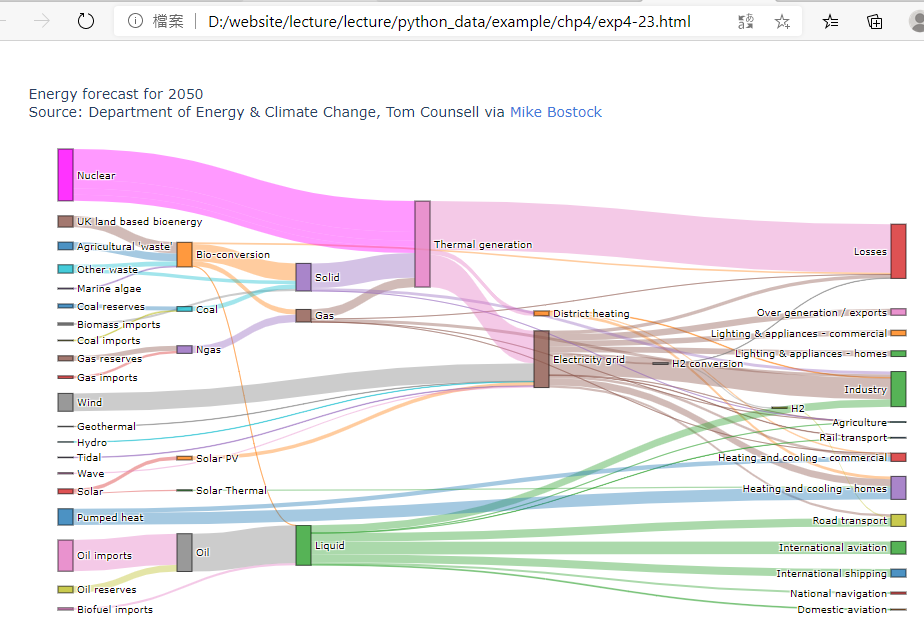
範例4-23:桑基圖
23.範例4-23:桑基圖Mike Bostock ",程式碼內容
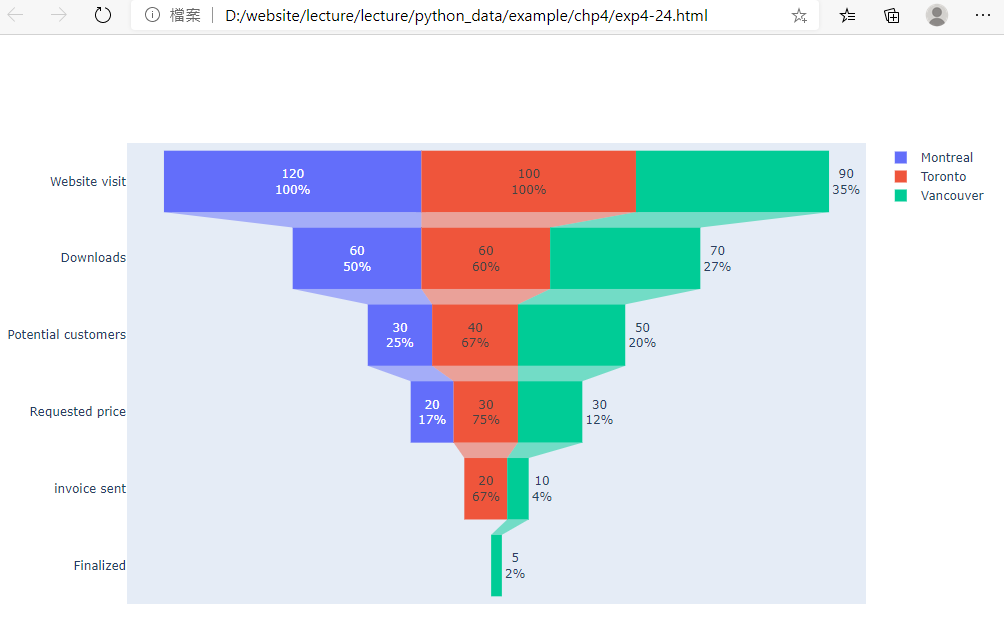
範例4-24:漏斗圖
24.範例4-24:漏斗圖程式碼內容
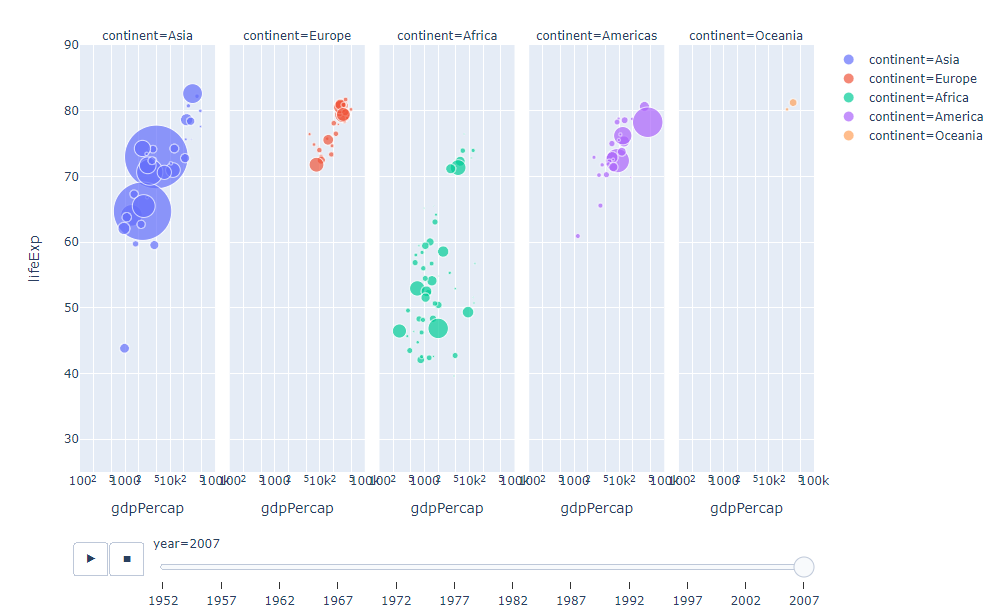
範例4-25:動畫控制
25.範例4-25:動畫控制程式碼內容
chp5.矩陣運算數學函數庫(Numpy) 目錄 Python大數據分析最重要的四個模組 1.Numpy簡介與安裝 範例5-1:一維矩陣 範例5-2:二維矩陣 範例5-3:設定矩陣元素起始值 範例5-4:建立矩陣元素值:range,arange,linspace 範例5-5:建立二維三維矩陣元素值:arange.reshape 範例5-6:矩陣的切割,切片(slice) 範例5-7:二維矩陣的部分區域的對應 範例5-8:使用另外一組矩陣數據來建立新的矩陣 範例5-9:查詢與設定矩陣的資料型態:dtype 11.矩陣基礎 範例5-10:矩陣的加減乘除,dot運算 範例5-11:兩個平面向量的內積,外積 14.統計的『平均值,變異數,標準差 範例5-12:矩陣的數據函數與統計函數 範例5-13:在矩陣中挑選你要的元素矩陣 範例5-14:不同大小矩陣的相加 範例5-15:python裡面的張量tensor,向量vector,純量scalar 張量tensor的幾何意義與坐標轉換 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
1.Numpy簡介與安裝
1.Numpy簡介與安裝
範例5-1:一維矩陣
2.一維矩陣:範例5-1程式碼內容
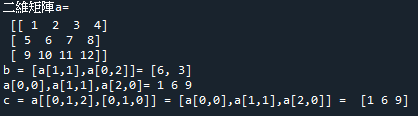
範例5-2:二維矩陣
3.範例5-2:二維矩陣程式碼內容
範例5-3:設定矩陣元素起始值
4.範例5-3:設定矩陣元素起始值程式碼內容
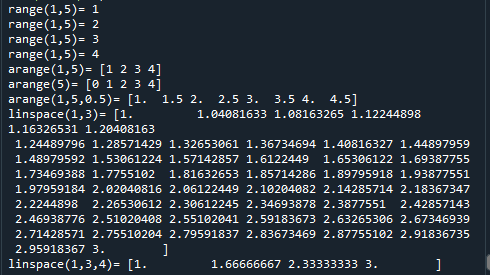
範例5-4:建立矩陣元素值(自動遞增遞減的數組):range,arange,linspace
5.範例5-4:建立矩陣元素值(自動遞增遞減的數組):range,arange,linspace程式碼內容
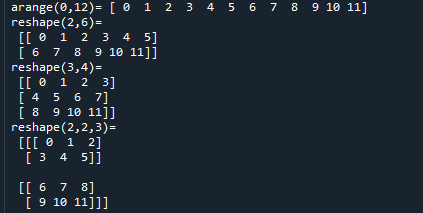
範例5-5:建立二維三維矩陣元素值(自動遞增遞減的數組):arange.reshape
6.範例5-5:建立二維三維矩陣元素值(自動遞增遞減的數組):arange.reshape程式碼內容
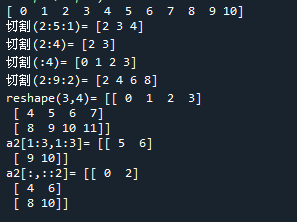
範例5-6:矩陣的切割,切片(slice)
7.範例5-6:矩陣的切割,切片(slice)程式碼內容
範例5-7:二維矩陣的部分區域的對應
8.範例5-7:二維矩陣的部分區域的對應程式碼內容
範例5-8:使用另外一組矩陣數據來建立新的矩陣
9.範例5-8:使用另外一組矩陣數據來建立新的矩陣程式碼內容
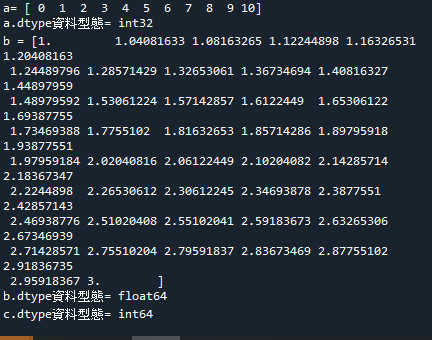
範例5-9:查詢與設定矩陣的資料型態:dtype
10.範例5-9:查詢與設定矩陣的資料型態:dtype程式碼內容
11.矩陣基礎
11.矩陣基礎矩陣基本運算pdf
範例5-10:矩陣的加減乘除,dot運算
12.範例5-10:矩陣的加減乘除,dot運算程式碼內容
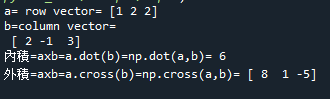
範例5-11:兩個平面向量的內積,外積
13.範例5-11:兩個平面向量的內積,外積程式碼內容
14.統計的『平均值,變異數,標準差』
14.統計的『平均值,變異數,標準差』
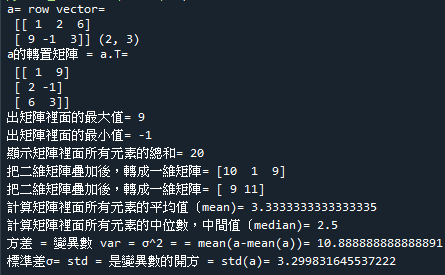
範例5-12:矩陣的數據函數與統計函數
15.範例5-12:矩陣的數據函數與統計函數程式碼內容
範例5-13:在矩陣中挑選你要的元素矩陣
16.範例5-13:在矩陣中挑選你要的元素矩陣程式碼內容
範例5-14:不同大小矩陣的相加
16.範例5-14:不同大小矩陣的相加程式碼內容
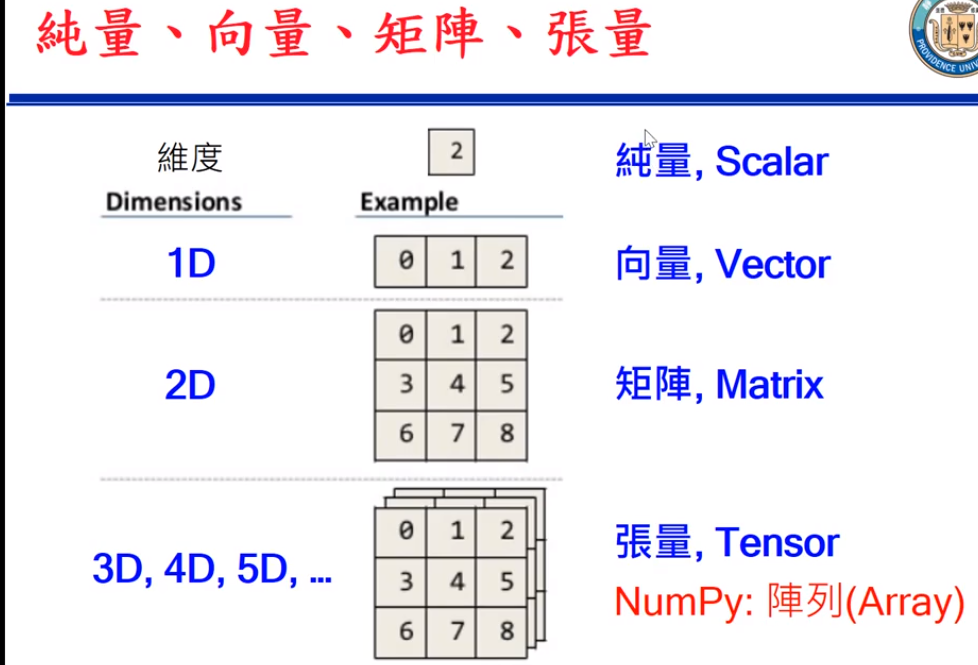
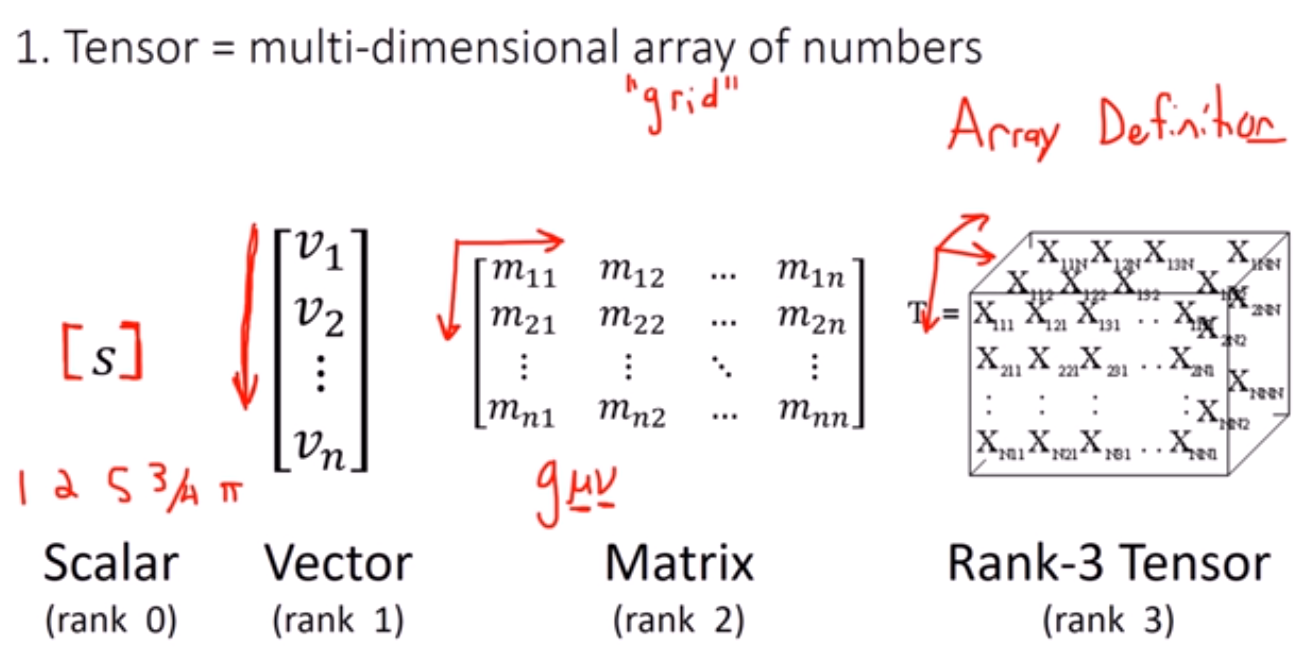
範例5-15:python裡面的張量tensor,向量vector,純量scalar
17.範例5-15:python裡面的張量tensor,向量vector,純量scalar程式碼內容
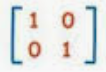
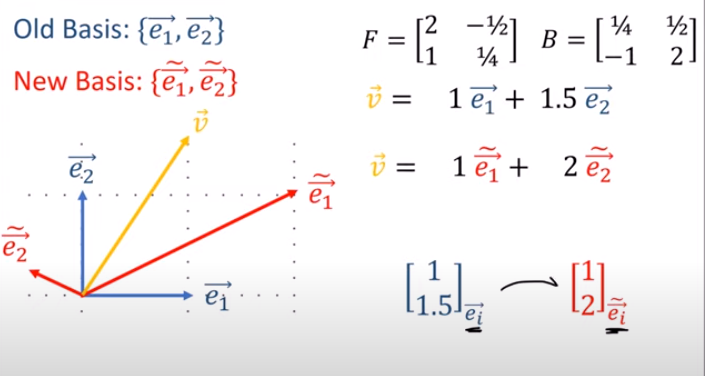
張量tensor的幾何意義與坐標轉換
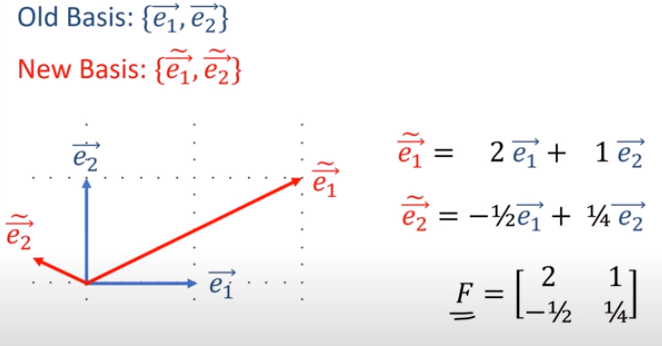
(1).張量tensor的幾何意義與坐標轉換影片:兩個2D坐標系統,如何轉換,以張量表示(Forward 正向轉換,Backward反向轉換) 影片:向量Vector用張量表示 影片:證明向量坐標轉換的轉換矩陣是contravariant逆變的:F,B矩陣逆變 From:各種正交坐標轉換:直角座標,圓柱座標,球座標
chp6.資料儲存與讀取1(txt,CSV、Excel、Google試算表) Python大數據分析最重要的四個模組 1.python讀取excel,csv有兩種方法 範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsx 範例6-4:讀取csv檔案score.csv,存檔scorecsv.csv 範例6-5:讀取html的表格table(2020 世界大學排名) 範例6-6:讀取cost.csv,計算總共花費多少錢 範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量) 範例6-8:讀取AAPL.xlsx股票檔案 範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案) 3.存取文字檔 範例6-6:讀取exp6-1.py的所有內容 範例6-7:使用迴圈,一行一行讀取exp6-1.py的所有內容 範例6-8:讀取目前目錄下所有檔案的文字內容 範例6-9:存入exp6-10.py,印出新年快樂 範例6-11:存入exp6-10.py,印出新年快樂,但是用try...except 範例6-12:把exp112-10.py,複製到copy.py檔案 4.存取csv:範例6-13:讀入一個已經存在的csv檔案 範例6-14:把第一行的標題結合資料數據,形成字典格式dict 範例6-15:新增一個新檔案,加入一筆標題,加入一筆記錄 範例6-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 範例6-17:已知字典變數數據,要寫入檔案 5.存取二進位檔案:範例6-18:把對聯文字,存入二進位檔案 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
1.python讀取excel,csv有兩種方法
1.python讀取excel,csv有兩種方法:
範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsx
7.範例6-3:讀取excel檔案score.xlsx,存檔score2.xlsxdownload score.xlsx 程式碼內容
範例6-4:讀取csv檔案score.csv,存檔scorecsv.csv
8.範例6-4:讀取csv檔案score.csv,存檔scorecsv.csvdownload score.csv 程式碼內容
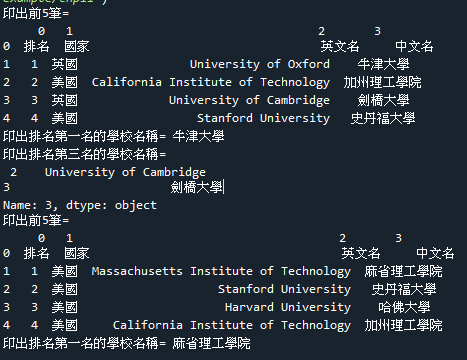
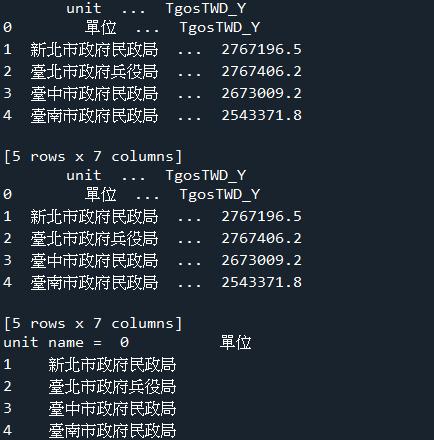
範例6-5:讀取html的表格table(2020 世界大學排名)
9.範例6-5:讀取html的表格table(2020 世界大學排名)程式碼內容
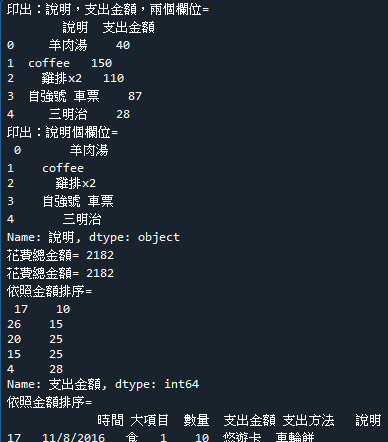
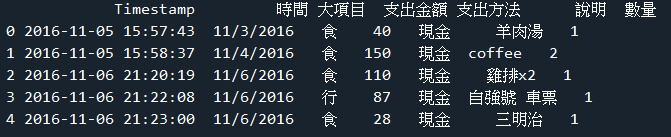
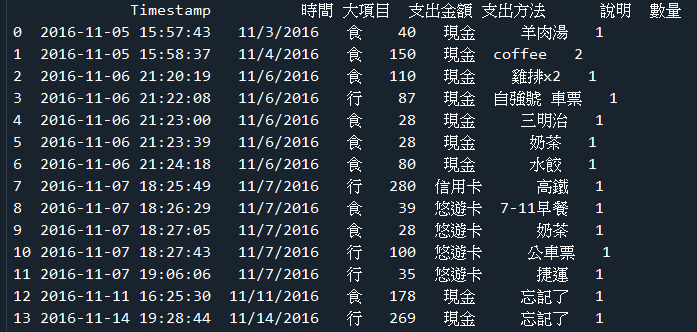
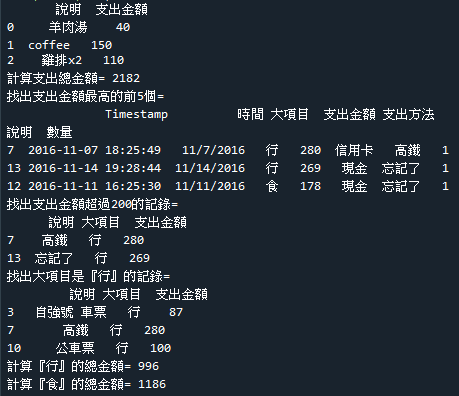
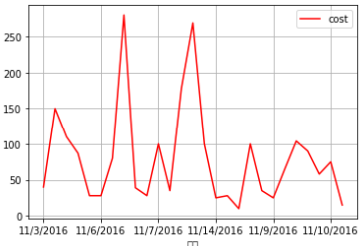
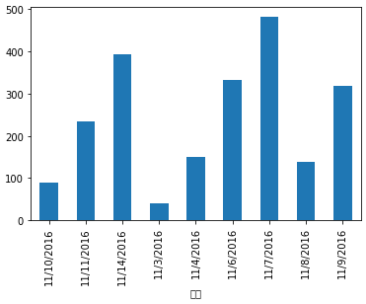
範例6-6:讀取cost.csv,計算總共花費多少錢
10.範例6-6:讀取cost.csv,計算總共花費多少錢download cost.csv 程式碼內容
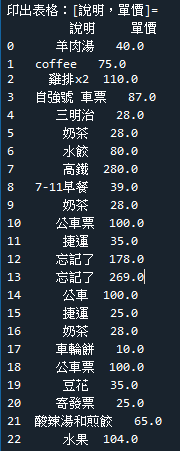
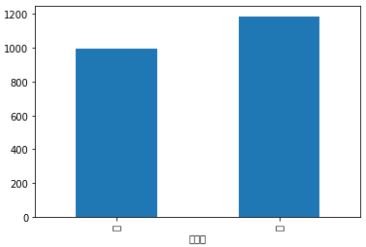
範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)
11.範例6-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)download cost.xlsx 程式碼內容
範例6-8:讀取AAPL.xlsx股票檔案
12.範例6-8:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案)
13.範例6-9:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
3.存取文字檔
3.存取文字檔
範例6-6:讀取exp6-1.py的所有內容
(1).範例6-6.pyexp6-1.py 程式碼內容
範例6-7:使用迴圈,一行一行讀取exp6-1.py的所有內容
(2).範例6-7.pyexp6-1.py 程式碼內容
範例6-8:讀取目前目錄下所有檔案的文字內容
(3).範例6-8.py程式碼內容
範例6-9:存入exp6-10.py,印出新年快樂
(4).範例6-9.py程式碼內容
範例6-11:存入exp6-10.py,印出新年快樂,但是用try...except
(5).範例6-11.py程式碼內容
範例6-12:把exp112-10.py,複製到copy.py檔案
6).範例6-12.py程式碼內容
4.存取csv:範例6-13:讀入一個已經存在的csv檔案
4.存取csv檔customer.csv 到exp6-11.py同一個目錄)程式碼內容
範例6-14:把第一行的標題結合資料數據,形成字典格式dict
(2).範例6-14.py程式碼內容
範例6-15:新增一個新檔案,加入一筆標題,加入一筆記錄
(3).範例6-15.py程式碼內容
範例6-16:開啟一個舊檔,加入一筆標題,加入一筆記錄
(4).範例6-16.py程式碼內容
範例6-17:已知字典變數數據,要寫入檔案
(5).範例6-17.py程式碼內容
範例6-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案)
13.範例11-9:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
chp7.資料儲存與讀取2(SQLite、MySQL) 1.python讀取mySQL有兩種方法 2.讀取資料庫Mysql(用MySQLdb函式庫:pymysql) 範例7-1:用pandas直接查詢讀取mySQL,並繪圖 範例7-2:查詢ch09資料庫的books資料表,列出所有書名,與價格 3.讀取SQLite資料庫的傳統方法 範例7-3:建立資料庫資料表stu,新增2筆資料,查詢所有的記錄 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
1.python讀取mySQL有兩種方法
1.python讀取mySQL有兩種方法:
2.讀取資料庫Mysql(用MySQLdb函式庫:pymysql)
2.讀取資料庫(Mysql)
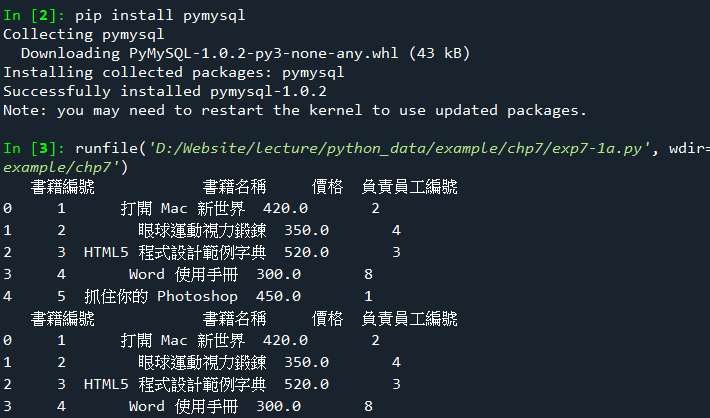
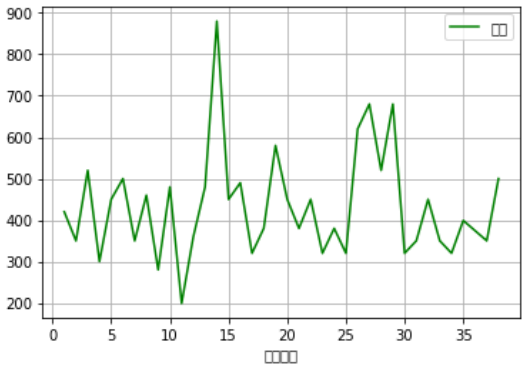
範例7-1:用pandas直接查詢讀取mySQL,並繪圖
16.範例7-1:用pandas直接查詢讀取mySQL,並繪圖下載資料庫ch09 程式碼內容(a) 程式碼內容(b)
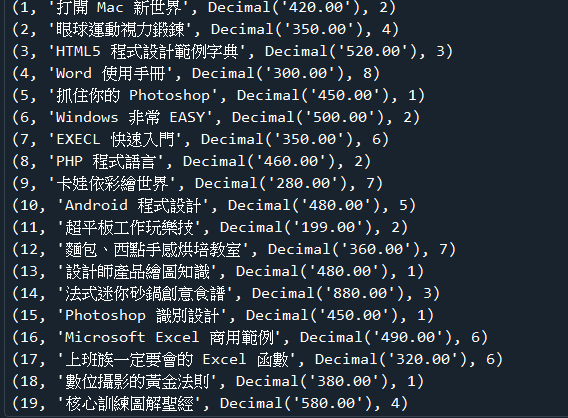
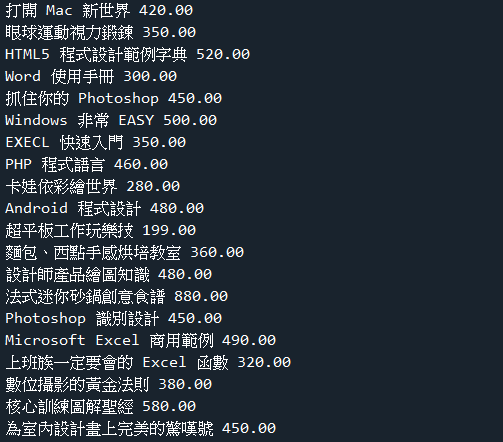
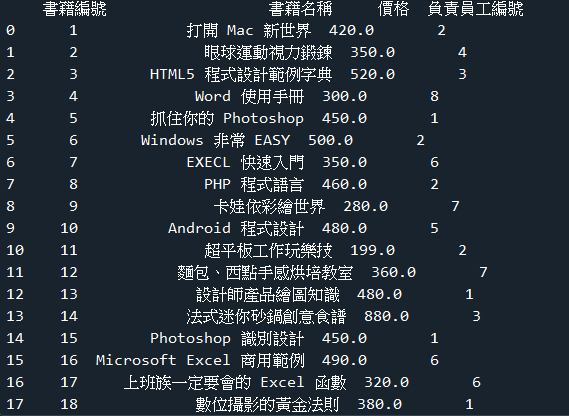
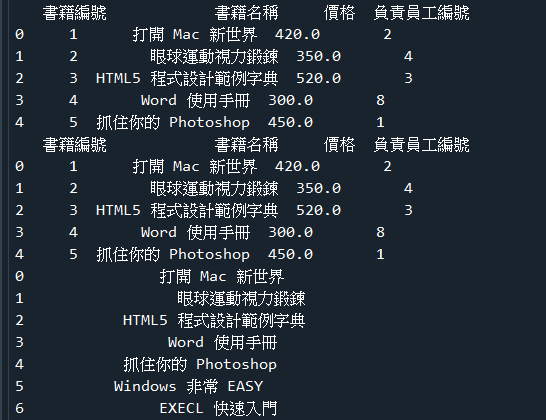
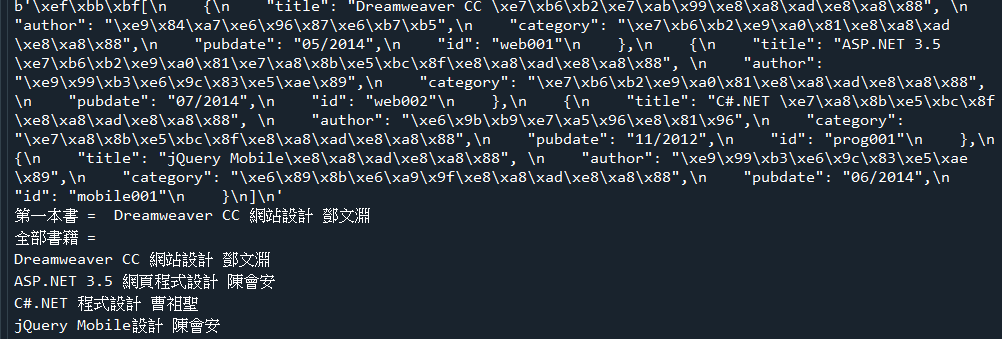
範例7-2:查詢ch09資料庫的books資料表,列出所有書名,與價格
☎範例7-2:查詢ch09資料庫的books資料表,列出所有書名,與價格下載資料庫ch09 )(資料表:books)下載資料庫ch09
1.程式碼內容(a)
3.讀取SQLite資料庫的傳統方法
1.讀取資料庫(SQLite)
範例7-3:建立資料庫資料表stu,新增2筆資料,查詢所有的記錄
☎範例7-3:建立資料庫資料表stu,新增2筆資料,查詢所有的記錄資料庫student.db 程式碼內容(b)
chp8.資料儲存與讀取3(存取xml,json) 上課範例 範例8-1:讀取json檔案有兩種方法 範例8-2:pandas讀取同一目錄的json檔案 範例8-3:pandas讀 取URL json檔案 觀摩範例 1.存取xml:模組:xml.etree.ElementTree 範例8-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 範例8-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 範例8-3:修改並存入xml 線上XML/JSON互相轉換工具 2.讀取網頁:request(url) 範例8-4:讀取網頁:web = request.urlopen(網址) 3.存取 json(模組:json) 範例8-5:轉成json:jumps。轉成dict:loads 範例8-6:讀取網絡上的json檔案 範例8-7:讀取電腦上的json檔案 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
範例8-1:讀取json檔案有兩種方法:
1.讀取json檔案有兩種方法:下載cost.json 程式碼內容(a)
範例8-2:pandas讀取同一目錄的json檔案
14.範例8-2:pandas讀取同一目錄的json檔案下載cost.json 程式碼內容(a) 下載cost.json 程式碼內容
範例8-3:pandas讀 取URL json檔案
15.範例8-3:pandas讀 取URL json檔案https://od.moi.gov.tw/od/data/api/EA28418E-8956-4790-BAF4-C2D3988266CC?$format=json 程式碼內容(a) 程式碼內容
1.存取xml:模組:xml.etree.ElementTree
1.存取xml
範例8-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料
☎方法1:範例8-1.pyperson.xml 的tag名:person的attributes(空值):{}的三個子元素
範例8-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信
☎方法2範例8-2.py程式碼內容
範例8-3:修改並存入xml
(3).修改並存入xml文檔程式碼內容
線上XML/JSON互相轉換工具
線上XML/JSON互相轉換工具:
2.讀取網頁:request(url)
2.讀取網頁:request(url)
範例8-4:讀取網頁:web = request.urlopen(網址)
☎範例8-4.py程式碼內容
3.存取 json(模組:json)
3.存取 json
範例8-5:轉成json:jumps。轉成dict:loads
(4).☎範例8-5.py程式碼內容
範例8-6:讀取網絡上的json檔案
(5).讀取網絡上的json檔案程式碼內容
範例8-7:讀取電腦上的json檔案
(6).讀取電腦上的json檔案程式碼內容
chp9.網絡大數據爬取與分析1(讀取網頁:request(url)) 2.讀取網頁:request(url) 範例9-1:讀取網頁:web = request.urlopen(網址) 3.存取 json(模組:json) 範例9-2:轉成json:jumps。轉成dict:loads 範例9-3:讀取網絡上的json檔案 範例9-4:讀取電腦上的json檔案 2.讀取網頁:request(url)
2.讀取網頁:request(url)
範例9-1:讀取網頁:web = request.urlopen(網址)
☎範例9-1.pyhttp://web.tsu.edu.tw/bin/home.php 程式碼內容(a) 程式碼內容(b)
3.存取 json(模組:json)
3.存取 json
範例9-2:轉成json:jumps。轉成dict:loads
(4).☎範例9-2.py程式碼內容(a) 程式碼內容(a)
範例9-3:讀取網絡上的json檔案
(5).讀取網絡上的json檔案http://acupun.site/lecture/jquery_phoneGap/json/book.json 程式碼內容(a) 程式碼內容(a)
範例9-4:讀取電腦上的json檔案
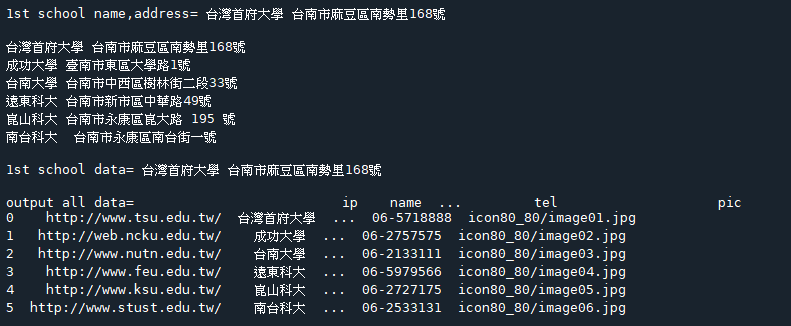
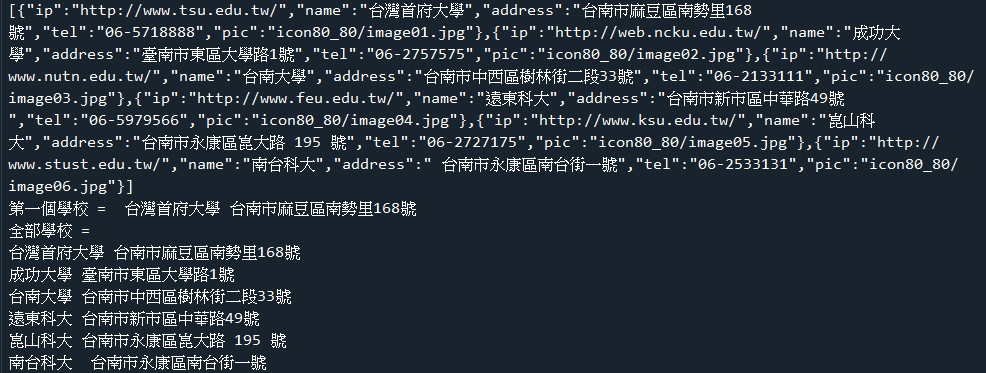
(6).讀取電腦上的json檔案下載school.json 下載school.json 程式碼內容(a) 程式碼內容(a)
chp10.網絡大數據爬取與分析2(網路爬蟲:BeautifulSoup) 3.網路爬蟲BeautifulSoup 範例10-1:讀取網頁標題 範例10-2:讀取網址的網頁 Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
1.網路爬蟲有兩種方法
1.網路爬蟲有兩種方法:
3.網路爬蟲BeautifulSoup
3.網路爬蟲BeautifulSoup: 讀取並分析html網頁標籤
範例10-1:讀取網頁標題
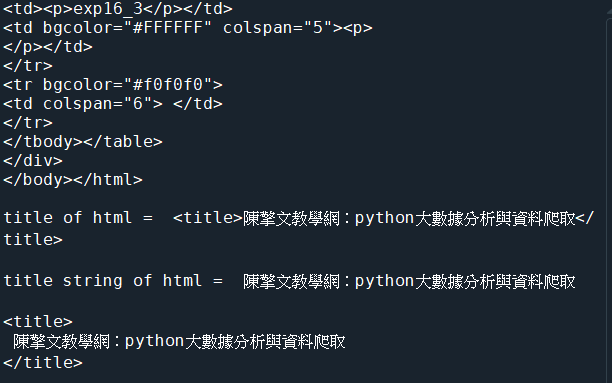
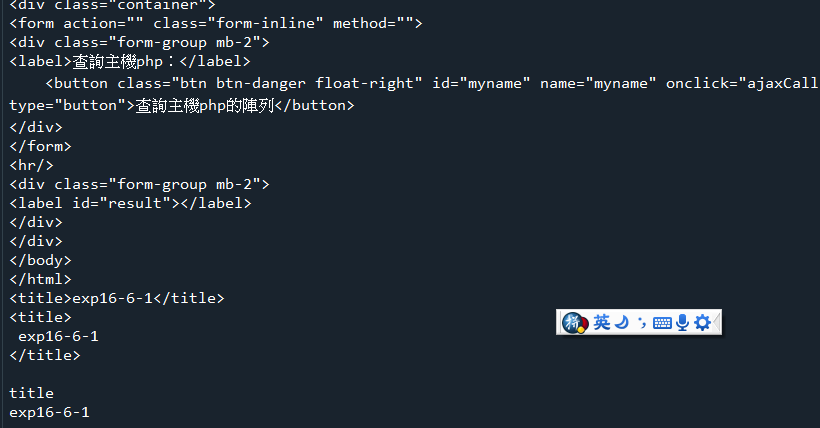
☎範例10-1.pyhttp://acupun.byethost7.com/phpexample/exp16-6-1.html 程式碼內容(a) 程式碼內容(a)
範例10-2:讀取網址的網頁
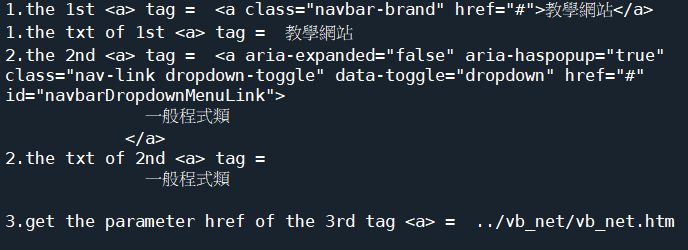
(4).讀取網址的網頁:https://acupun.site/lecture/python/index.htm' 程式碼內容(a) 程式碼內容(b)
chp11.網絡大數據爬取與分析3(Pandas數據分析與資料存取) 1.大數據分析的工具 Python大數據分析最重要的四個模組 3.Pandas基礎功能: 4.Pandas的資料結構 範例11-1:建立一維陣列資料Series 範例11-1:用pandas建立DataFrame的三種方法 範例11-2:把二維字典(dict)資料,轉成DataFrame,找出分數>80 範例11-3:讀取excel檔案score.xlsx,存檔 範例11-4:讀取csv檔案score.csv,存檔 範例11-5:讀取html的表格table 範例11-6:讀取cost.csv,計算總共花費多少錢 範例11-7:讀取cost.xlsx,計算新欄位=單價 範例11-8:讀取AAPL.xlsx股票檔案 範例11-9:結合pandas 與 matplotlib 畫圖股票線圖 範例11-10:pandas讀取同一目錄的json檔案 範例11-11:pandas讀 取URL json檔案 範例11-12:用pandas直接查詢讀取mySQL 範例11-13:用pandas把dataframe儲存成json檔案 1.大數據分析的工具
1.大數據分析的工具:
Python大數據分析最重要的四個模組
1.Python大數據分析最重要的四個模組
3.Pandas基礎功能:
2.Pandas介紹https://pandas.pydata.org/ ,上面提供很多範例,
4.Pandas的資料結構
4.Pandas的資料結構
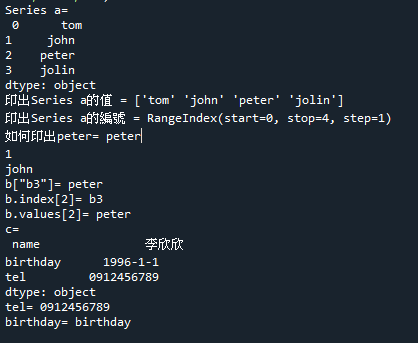
範例11-1:建立一維陣列資料Series
5.範例11-1:建立一維陣列資料Series程式碼內容
範例11-1:用pandas建立DataFrame的三種方法
17.範例11-1:用pandas建立DataFrame的三種方法程式碼內容
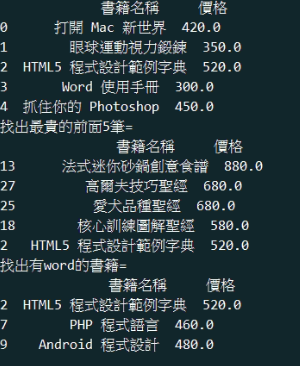
範例11-2:把二維字典(dict)資料,轉成DataFrame,找出某位個人資料,找出分數>80,依照字母排序
6.範例11-2:把二維字典(dict)資料,轉成DataFrame,找出某位個人資料,找出分數>80,依照字母排序程式碼內容
範例11-3:讀取excel檔案score.xlsx,存檔score2.xlsx
7.範例11-3:讀取excel檔案score.xlsx,存檔score2.xlsx程式碼內容
範例11-4:讀取csv檔案score.csv,存檔scorecsv.csv
8.範例11-4:讀取csv檔案score.csv,存檔scorecsv.csv程式碼內容
範例11-5:讀取html的表格table(2020 世界大學排名)
9.範例11-5:讀取html的表格table(2020 世界大學排名)程式碼內容
範例11-6:讀取cost.csv,計算總共花費多少錢
10.範例11-6:讀取cost.csv,計算總共花費多少錢程式碼內容
範例11-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)
11.範例11-7:讀取cost.xlsx,計算新欄位=單價(支出金額/數量)程式碼內容
範例11-8:讀取AAPL.xlsx股票檔案
12.範例11-8:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
範例11-9:結合pandas 與 matplotlib 畫圖股票線圖(讀取AAPL.xlsx股票檔案)
13.範例11-9:畫圖股票線圖(讀取AAPL.xlsx 股票檔案)程式碼內容
範例11-10:pandas讀取同一目錄的json檔案
14.範例11-10:pandas讀取同一目錄的json檔案程式碼內容
範例11-11:pandas讀 取URL json檔案
15.範例11-11:pandas讀 取URL json檔案程式碼內容
範例11-12:用pandas直接查詢讀取mySQL
16.範例11-12:用pandas直接查詢讀取mySQL程式碼內容
範例11-13:用pandas把dataframe儲存成json檔案:df.to_json(filename)
17.範例11-13:用pandas把dataframe儲存成json檔案:df.to_json(filename)程式碼內容
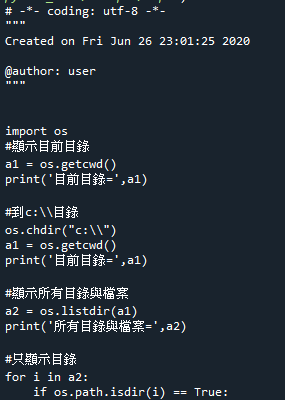
chp12.網絡大數據爬取與分析4(用正規式搜尋網頁的email,jpg訊息) 1.資料夾模組:os 範例12-1:建立目錄,刪除目錄,顯示檔案 範例12-2:把該目錄下方的資料夾以串列顯示 範例12-3:到某個目錄查詢指定檔案名稱 範例12-4:顯示目前目錄下的完整路徑(目錄+檔案名稱) 範例12-5:更有效率的顯示目前目錄下的完整路徑 3.存取文字檔 範例12-6:讀取exp12-1.py的所有內容 範例12-7:使用迴圈,一行一行讀取exp12-1.py的所有內容 範例12-8:讀取目前目錄下所有檔案的文字內容 範例12-9:存入exp12-10.py,印出新年快樂 範例12-11:存入exp12-10.py,印出新年快樂,但是用try...except 範例12-12:把exp112-10.py,複製到copy.py檔案 範例12-13:4.存取csv:讀入一個已經存在的csv檔案 範例12-14:把第一行的標題結合資料數據,形成字典格式dict 範例12-15:新增一個新檔案,加入一筆標題,加入一筆記錄 範例12-16:開啟一個舊檔,加入一筆標題,加入一筆記錄 範例12-17:已知字典變數數據,要寫入檔案 5.存取二進位檔案:範例12-18:把對聯文字,存入二進位檔案 1.資料夾模組:os
1.功能:刪除資料夾(檔案),儲存資料夾(檔案),修改資料夾(檔案),查詢資料夾(檔案)
範例12-1:建立目錄,刪除目錄,顯示檔案
(2).範例12-1.py程式碼內容
範例12-2:把該目錄下方的資料夾以串列顯示
(3).範例12-2.py程式碼內容
範例12-3:到某個目錄查詢指定檔案名稱
2.模組:glob程式碼內容
範例12-4:顯示目前目錄下的完整路徑(目錄+檔案名稱)
(5).範例12-4.py程式碼內容
範例12-5:更有效率的顯示目前目錄下的完整路徑
(6).範例12-5.py程式碼內容
3.存取文字檔
3.存取文字檔
範例12-6:讀取exp12-1.py的所有內容
(1).範例12-6.py程式碼內容
範例12-7:使用迴圈,一行一行讀取exp12-1.py的所有內容
(2).範例12-7.py程式碼內容
範例12-8:讀取目前目錄下所有檔案的文字內容
(3).範例12-8.py程式碼內容
範例12-9:存入exp12-10.py,印出新年快樂
(4).範例12-9.py程式碼內容
範例12-11:存入exp12-10.py,印出新年快樂,但是用try...except
(5).範例12-11.py程式碼內容
範例12-12:把exp112-10.py,複製到copy.py檔案
6).範例12-12.py程式碼內容
4.存取csv:範例12-13:讀入一個已經存在的csv檔案
4.存取csv檔customer.csv 到exp12-11.py同一個目錄)程式碼內容
範例12-14:把第一行的標題結合資料數據,形成字典格式dict
(2).範例12-14.py程式碼內容
範例12-15:新增一個新檔案,加入一筆標題,加入一筆記錄
(3).範例12-15.py程式碼內容
範例12-16:開啟一個舊檔,加入一筆標題,加入一筆記錄
(4).範例12-16.py程式碼內容
範例12-17:已知字典變數數據,要寫入檔案
(5).範例12-17.py程式碼內容
5.存取二進位檔案:範例12-18:把對聯文字,存入二進位檔案
5.存取二進位檔案程式碼內容
chp13.網絡大數據爬取與分析5(Selenium自動化網頁操作) 1.日期時間函式庫 範例13-1:模組datetime(顯示日期,時間 範例13-2:模組date(只能顯示日期) 範例13-3:模組timedelta(間隔日期,時間) 範例13-4:傳回自1970年1月1日凌晨0:0:0開始至今的秒數 範例13-5:計算呼叫某個函式所需要的時間 2.可以迭代(iterate)的函式庫= itertools,函式enumerate,zip,filter,map,reduce 範例13-6:顯示陣列 範例13-7:zip(a,b)是結合兩個可迭代物 範例13-8:模組itertools:給定起始值,遞增值,就可以產生無窮數列 範例13-9:filter(過濾函數def或lambda,資料列) 範例13-10:過濾模組map 範例13-11:操作每個元素模組reduce 範例13-12:套件collections-模組OderedDict:可將兩個串列,合併形成成一個字典dict 範例13-13:模組deque:操作可迭代資料列,新增,刪除,反轉 例13-14:模組dCounter:可計算可迭代資料列相同元素的次 1.日期時間函式庫
1.日期時間函式庫
範例13-1:模組datetime(顯示日期,時間
(2).範例13-1:模組datetime(顯示日期,時間)程式碼內容
範例13-2:模組date(只能顯示日期)
(3).模組date(只能顯示日期)程式碼內容
範例13-3:模組timedelta(間隔日期,時間)
(4).模組timedelta(間隔日期,時間)程式碼內容
範例13-4:傳回自1970年1月1日凌晨0:0:0開始至今的秒數
(5).模組time(時間)程式碼內容
範例13-5:計算呼叫某個函式所需要的時間
範例13-5.py程式碼內容
2.可以迭代(iterate)的函式庫= itertools,函式enumerate,zip,filter,map,reduce
2.可以迭代(iterate)的函式庫
範例13-6:顯示陣列
☎範例13-6.py程式碼內容
範例13-7:zip(a,b)是結合兩個可迭代物
(3).zip(a,b)是結合兩個可迭代物件程式碼內容
範例13-8:模組itertools:給定起始值,遞增值,就可以產生無窮數列
(4).模組itertools程式碼內容
範例13-9:filter(過濾函數def或lambda,資料列)
(5).過濾模組filter程式碼內容
範例13-10:過濾模組map
(6).過濾模組map程式碼內容
範例13-11:操作每個元素模組reduce
(7).操作每個元素模組reduce程式碼內容
範例13-12:套件collections-模組OderedDict:可將兩個串列,合併形成成一個字典dict
3.套件collections程式碼內容
範例13-13:模組deque:操作可迭代資料列,新增,刪除,反轉
(2).模組deque程式碼內容
例13-14:模組dCounter:可計算可迭代資料列相同元素的次
(3).模組dCounter程式碼內容
chp14.數學函數庫math,sympy,微分,積分,偏微分 1.存取xml:模組:xml.etree.ElementTree 範例14-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料 範例14-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信 範例14-3:修改並存入xml 線上XML/JSON互相轉換工具 2.讀取網頁:request(url) 範例14-4:讀取網頁:web = request.urlopen(網址) 3.存取 json(模組:json) 範例14-5:轉成json:jumps。轉成dict:loads 範例14-6:讀取網絡上的json檔案 範例14-7:讀取電腦上的json檔案 3.網路爬蟲BeautifulSoup 範例14-8:讀取網頁標題 範例14-9:讀取網址的網頁 1.存取xml:模組:xml.etree.ElementTree
1.python的數學函數庫:math,sympy,cmath (1)math: 功能:乘方、開方、對數,冪函數與對數函數,三角函數,角度轉換,雙曲函數,特殊函數,常量,cos,sin,e,log,tan,pow Math模組 sqrt(x) 傳回 x 的平方根 pow(x, y) 傳回 x 的 y 次方 exp(x) 傳回 x 的自然指數 expm1(x) 傳回 x 的自然指數-1 (在 x 接近 0 時仍有精確值) log(x [, b]) 傳回 x 以 b 為基底的對數 (預設 b=e 自然對數) log10(x) 傳回 x 的常用對數 (以 10 為底數) degrees(x) 傳回弧度 x 的角度 (degree) radians(x) 傳回角度 x 的弧度 (radian) dist(p, q) 傳回兩個座標點 p, q 的歐幾里得距離 (畢式定理斜邊) hypot(coor) 傳回座標序列 coor 的歐幾里得距離 sin(x) 傳回 x 的正弦值 cos(x) 傳回 x 的餘弦值 tan(x) 傳回 x 的正切值 asin(x) 傳回 x 的反正弦值 (sin 的反函數) acos(x) 傳回 x 的反餘弦值 (cos 的反函數) atan(x) 傳回 x 的反正切值 (tan 的反函數) atan2(y, x) 傳回 y/x 的反正切值 (tan 的反函數)=atan(y/x) sinh(x) 傳回 x 的雙曲正弦值 cosh(x) 傳回 x 的雙曲餘弦值 tanh(x) 傳回 x 的雙曲正切值 asinh(x) 傳回 x 的反雙曲正弦值=log(x+sqrt(x**2+1)) acosh(x) 傳回 x 的反雙曲餘弦值=log(x+sqrt(x**2-1)) atanh(x) 傳回 x 的反雙曲正切值=1/2*log((1+x)/(1-x)) fabs(x) 傳回 x 的絕對值 (或稱模數, modulus) floor(x) 傳回浮點數 x 的向下取整數 (即小於 x 之最大整數) ceil(x) 傳回浮點數 x 的向上取整數 (即大於 x 之最小整數) trunc(x) 傳回浮點數 x 的整數部分 (捨去小數) modf(x) 傳回浮點數 x 的 (小數, 整數) 元組 factorial(x) 傳回 x 階乘 (x!, x=整數) gcd(x, y) 傳回整數 x, y 之最大公因數 comb(n, k) 傳回 n 取 k 的組合數 (不依序不重複) perm(n, k) 傳回 n 取 k 的組合數 (依序不重複) modf(x, y) 傳回 x/y 之精確餘數 (浮點數 float) fsum(iter) 傳回可迭代數值 iter 之精確總和 isclose(x, y) 若 a, b 值很接近傳回 True (預設差小於 1e-9) isfinite(x) 若 x 不是 nan 或 inf 傳回 True, 否則 False isnan(x) 若 x 為 nan 傳回 True, 否則 False isinf(x) 若 x 為 inf 傳回 True, 否則 False (2)sympy: Sympy是一個數學符號庫(sym代表了symbol,符號),包括了積分,微分方程,三角等各種數學運算方法,是工科最基本的數學函數庫,用起來媲美matlab,而且其精度比math函數庫精確。 功能: simplify運算式化簡,solve方程自動求解 limit求極限,diff求導 dsolve()計算微分方程 intergrate積分計算:1.定積分,2.不定積分,3.雙重定積分,4. 雙重不定積分 (3)cmath:專門用來處理複數運算。
範例14-1:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信資料
☎方法1:範例14-1.pyperson.xml 的tag名:person的attributes(空值):{}的三個子元素
範例14-2:讀取person.xml的所有每個節點資訊,查詢所有的mail,查詢卓水信
☎方法2範例14-2.py程式碼內容
範例14-3:修改並存入xml
(3).修改並存入xml文檔程式碼內容
線上XML/JSON互相轉換工具
線上XML/JSON互相轉換工具:
2.讀取網頁:request(url)
2.讀取網頁:request(url)
範例14-4:讀取網頁:web = request.urlopen(網址)
☎範例14-4.py程式碼內容
3.存取 json(模組:json)
3.存取 json
範例14-5:轉成json:jumps。轉成dict:loads
(4).☎範例14-5.py程式碼內容
範例14-6:讀取網絡上的json檔案
(5).讀取網絡上的json檔案程式碼內容
範例14-7:讀取電腦上的json檔案
(6).讀取電腦上的json檔案程式碼內容
3.網路爬蟲BeautifulSoup
3.網路爬蟲BeautifulSoup: 讀取並分析html網頁標籤
範例14-8:讀取網頁標題
☎範例14-8.py程式碼內容
範例14-9:讀取網址的網頁
(4).讀取網址的網頁:程式碼內容
chp7.讀取資料庫(SQLite, Mysql) 1.讀取資料庫(SQLite) 範例15-1:建立資料庫資料表stu,新增2筆資料,查詢所有的記錄 2.讀取資料庫(Mysql) 範例15-2:查詢ch09資料庫的books資料表,列出所有書名,與價格 1.讀取資料庫(SQLite)
1.讀取資料庫(SQLite)
範例15-1:建立資料庫資料表stu,新增2筆資料,查詢所有的記錄
☎(3).範例15-1.py程式碼內容
2.讀取資料庫(Mysql)
2.讀取資料庫(Mysql)
範例15-2:查詢ch09資料庫的books資料表,列出所有書名,與價格
☎(6).範例15-2.py程式碼內容
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_2
exp16_3